目次
ファイルを作成し、書き込む
import csv
with open('test2.csv', 'w', encoding='utf8', newline='') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(('number', 'number plus 2', 'number times 2'))
for i in range(10):
writer.writerow((i, i+2, i*2))
# 参考)フォルダ内のファイルを出力したい場合
# 上記の場合、CSVで出力するがExcelで開くと化ける(理由:ShiftJisで開かれるため)
# よってCSV出力の場合、encodedecodeErrorになることがあるため、pandasで出力したほうがよさそう
f_list = []
for f in FOLDER.rglob('*.*'):
file_name = f.name
file_suffix = f.suffix
file_fullpath = str(f)
f_list.append((file_name, file_suffix, file_fullpath))
df = pd.DataFrame(f_list, columns=header)
df.to_excel(path)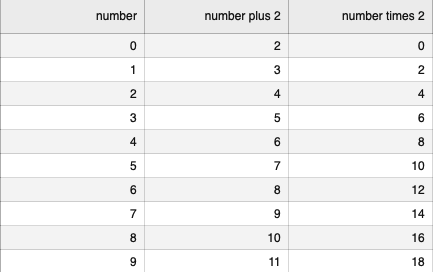
HTMLテーブルを読み込んでCSVで書き出す
- HTMLテーブルのデータをそのまま取得し、CSVファイルに保存するやり方
- http://en.wikipedia.org/wiki/Comparison_of_text_editors
<手順>
- Web(htmlテーブルあり)を開く
- bs4でパース
- table構造を取り出す
- rowsを取り出す
- CSVファイルに書き込む準備(csv.readerOBJをつくる)
- rowsからth,td要素を取出し、セル値を取り出したものをリストに追加(1行ずつ)
- リストをcsvOBJにwrite
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://en.wikipedia.org/wiki/Comparison_of_text_editors')
bs = BeautifulSoup(html, 'html.parser')
# タグtableのクラス属性「wikitable」の0番目のオブジェクトを取得
table = bs.find_all('table', {'class':'wikitable'})[0]
rows = table.find_all('tr') # 行
csvFile = open('editors.csv', 'wt+')
writer = csv.writer(csvFile)
try:
for row in rows:
csvRow = []
for cell in row.find_all(['td', 'th']): # 列の要素を取り出す
csvRow.append(cell.get_text()) # セルの値を取り出す
writer.writerow(csvRow) # 行ごとに処理しているため、writerow
finally:
csvFile.close()TABLE構造
- tr : table row
- th: table header
- td: table data
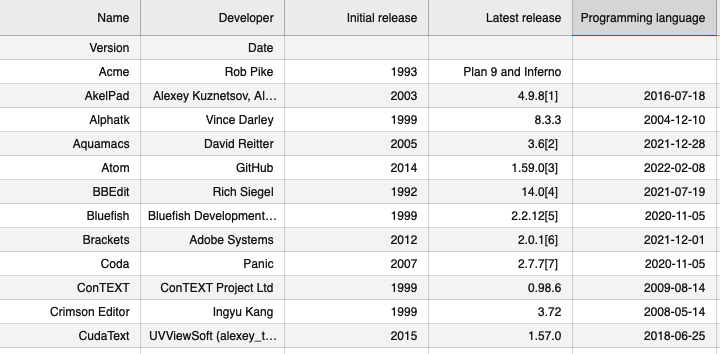
editors.csv
Webから文字列で取得し、StringIOオブジェクトでラップすればファイルとして扱える
- このやり方は、取得後にCSVに保存→読み込むことなく、オブジェクトをそのまま扱える
- https://pythonscraping.com/files/MontyPythonAlbums.csv

csv.reader(StringIO(data))
from urllib.request import urlopen
from io import StringIO
import csv
data = urlopen('http://pythonscraping.com/files/MontyPythonAlbums.csv')\
.read().decode('ascii', 'ignore')
dataFile = StringIO(data)
# csv.readerが返すオブジェクトはイテレート可能
csvReader = csv.reader(dataFile)
for row in csvReader:
print(row)- StringIO
- 文字列をファイルのように扱える
- ファイルを作るまでもない、作るのが面倒くさい時に活躍
- 文字列→(
encode)→バイト文字列- 符号化
- Unicode
- バイト文字列→(
decode)→文字列- 複合化
- UTF-8、ASCII、Shift-JIS、cp932など
出力結果
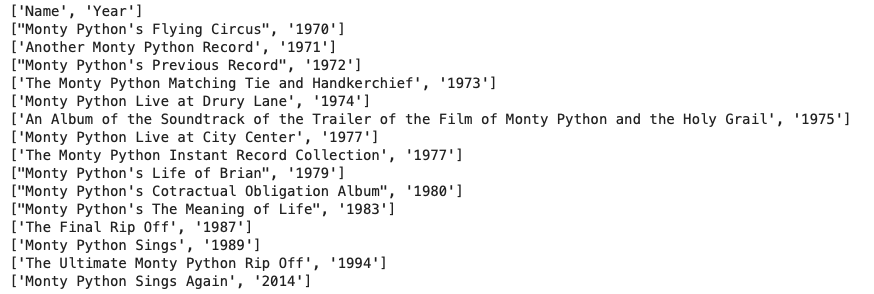
- 上記の場合、ヘッダーである[‘Name’, ‘Year’]が含まれており、本来は含めたくないこともある
- その場合、csvReaderの第1行をスキップするか、処理を書くかだが
DictReaderを利用すれば良い
csv.DictReader(StringIO(data))
# 上部割愛
dictReader = csv.DictReader(dataFile)
print(dictReader.fieldnames)
# ['Name', 'Year']
# DictReaderの場合、リストではなく辞書オブジェクトが返される
for row in dictReadaer:
print(row)
# >> {'Name': "Monty Python's Flying Circus", 'Year': '1970'}
# >> {'Name': 'Another Monty Python Record', 'Year': '1971'}
# >> {'Name': "Monty Python's Previous Record", 'Year': '1972'}
# >> {'Name': 'The Monty Python Matching Tie and Handkerchief', 'Year': '1973'}pandasでStringIOを読み込む
from io import StringIO
import pandas as pd
txt = """
number,name,score
1,hoge,100
2,fuga,200
3,piyo,300
"""
df = pd.read_csv(StringIO(txt), index_col="number")
print(df)