目次
用語集
- リスト
抽象データ型で、格納される要素の並び順を保持するデータ構造 - 配列
連続したメモリー領域に要素を保持し、各要素にインデックスでアクセスできるデータ構造 - 均質なデータ構造
整数や文字列などのうち、1種類のデータ型だけ格納できるデータ構造 - 混合可変長配列
実行中にサイズを変更でき、複数の異なるデータ型を格納できる配列 - 可変長配列
実行中にサイズを変更できる配列 - 混合配列
複数の異なるデータ型を格納できる配列 - ベースアドレス
配列先頭のメモリーアドレス - 一次元配列
要素に1つのインデックスでアクセスできる配列 - 多次元配列
要素の複数のインデックスでアクセスできる配列 - オーバーアロケーション
配列にいま必要な要素数よりも多くのメモリーを確保しておき、要素の追加時に空きスペースを利用する方法 - set
重複しない要素を格納するPythonの組み込みのデータ型
配列の要素
- 配列の要素は、インデックスというユニークな整数によってアクセスできる
- インデックスの最初の位置は0(Python)
- 配列の先頭のメモリーアドレスはベースアドレスとよぶ
- 配列に新しい要素を格納するとき、以下の計算式でベースアドレスとインデックスを計算して格納先のアドレスを算出する
ベースアドレス + ( インデックス × 要素1つに必要なメモリーサイズ )
- 配列から要素を取得するときにも、この数式でメモリーアドレスを計算している
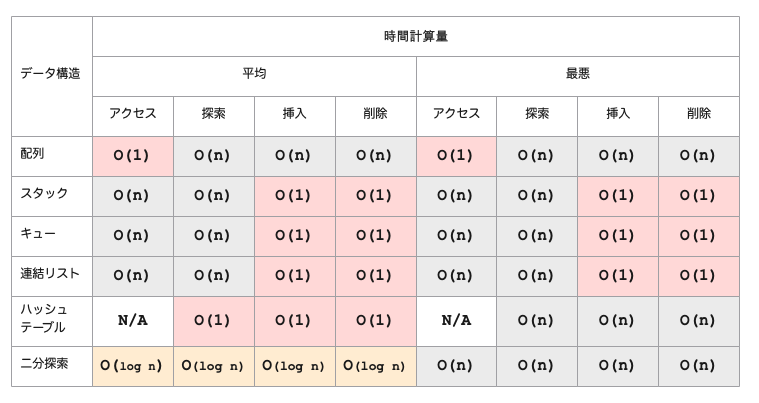
配列のパフォーマンス
- 配列の要素にインデックスでアクセスする場合、上記のメモリーアドレス計算(多次元配列は少し違う)によって、インデックスがいくつでも定数時間
O(1)でアクセスできる - これは、配列内の要素数がどれだけ膨大であっても、一定の時間でメモリーアドレスを計算できる
- ソートされていない配列の要素を検索する場合、オーダーは
O(n)です - 配列のすべての要素を確認して探している値かどうかをチェックするからです
- ソート済みの配列から要素を検索する場合は、
O(log n)です
配列の操作の実行時間
- 配列の要素へのアクセスや値の変更は
O(1)で非常に高速だが - 配列の形を変える変更(要素の追加や削除)は
O(n)です - 配列では連続したメモリー領域に要素を格納しているため、その途中に要素を追加するには元々そこにあった要素以降をすべて後ろにずらす必要があるためで、効率が悪い作業になる
- 小さい配列の場合、要素を移動させることはそれほど問題にならないが、大きい配列の任意の位置に(特に先頭付近に)要素を追加する場合、メモリーのコピーに多大な時間を消費してしまう
- 要素の追加は、配列のサイズがあらかじめ決められている静的データ構造の配列にとって、さらに深刻
- サイズを超えて要素を追加したい場合、連続する後続のメモリー領域が空いていれば追加分を確保する方法もあるが、そこが空いているかは保証できない
- 「配列」は頻繁にデータを追加するような大きいデータセットを扱うのには最適ではない
- 配列に要素を追加する操作は
0(n)です - 要素の追加を効率良く行うには、次章の連結リストをつかうとよい
- 配列に要素を挿入すると、それ以降のインデックスが変わってしまう
- インデックスを変えたくない場合、Pythonでは辞書を使うのが良い
配列を作成する
- pythonでプログラミングをしていれば、配列を必要とするほとんどで
listが使える - よりパフォーマンスを高めるために均質な配列(一種類のみ)を使いたければ、Python組み込みの
arrayモジュールが使える - 早速使ってみる
import array
arr = array.array('f', (1.0, 1.5, 2.0, 0.3))
print(arr[1])
# >>>1.5https://docs.python.org/ja/3/library/array.html
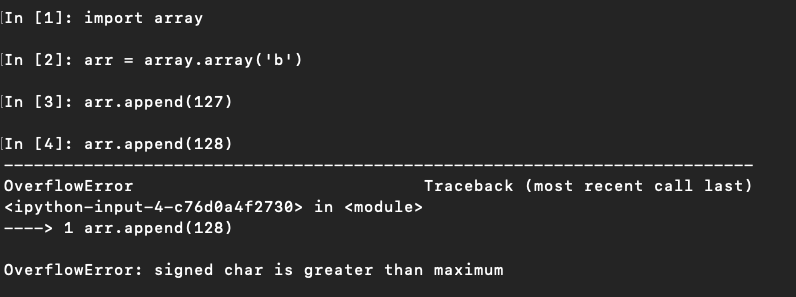
- 型コード「b」の場合、その最小サイズ(バイト数)は「1B」
- 1B=8bitだから、2の8乗で256まで使えるのでは?と思ったが
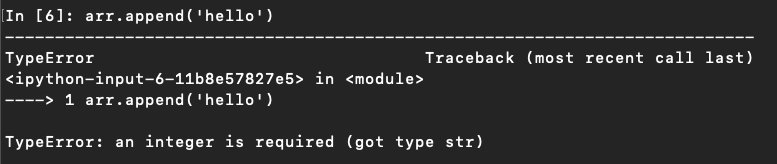
- arr.append(128)でオーバーアロケーションエラーになってしまう、なぜ?
- なぜかはこちらを参照→データ型の範囲
- 「b」つまり「signed char」の値の範囲は「-128 ~ 127」になっている模様
型コード「i」「b」「リスト」で比較してみる(参照HP)
- 型コード「i」(Cの型:singed int)→最小サイズ:2B
- 型コード「b」(Cの型:signed char)→最小サイズ:1B

- リストよりもメモリーを節約されている(b<i<リスト)
- もちろん、listと違い、arrayに最初に指定したのと違うデータ型を格納するとエラーが発生する
- 速度が必要な場合、Numpyをつかう。Numpyは低水準を扱えるC言語に近い高速な配列を提供する
ゼロを移動する
- 問題:次のリストにあるすべてのゼロを末尾に移動し、残りの数字の並びは変えない
[8, 0, 3, 0, 12] → 結果 [8, 3, 12, 0, 0] になればよい
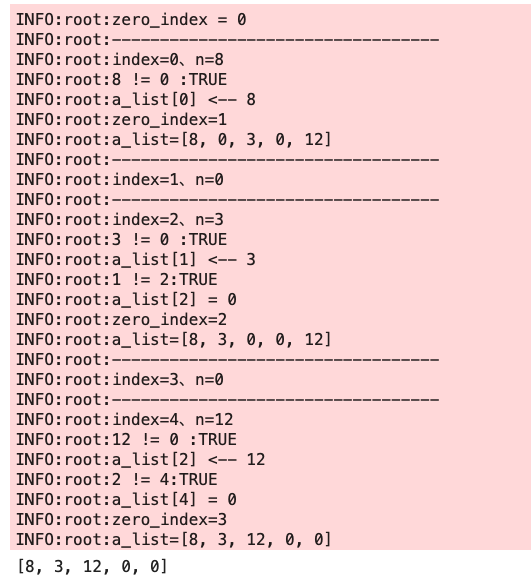
def move_zeros(a_list):
zero_index = 0
for index, n in enumerate(a_list):
if n != 0:
a_list[zero_index] = n
if zero_index != index:
a_list[index] = 0 # (ゼロでない数字の)元のインデックスを「ゼロ」を変更(移動)
zero_index += 1
return a_list
a_list = [8, 0, 3, 0, 12]
move_zeros(a_list)
print(a_list)
# >>> [8, 3, 12, 0, 0]- ログを取るとこんな感じで回っている
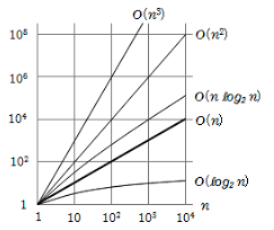
- このアルゴリズムの時間計算量はループが1つだけあるため、
O(n) になる
2つのリストを統合する
- 問題:以下の映画のタイトルと評価があるとする。この2つのリストを1つに統合する
movie_list = [
'インターステラー', 'インセプション', 'プレステージ',
'インソムニア', 'バットマンビギンズ'
]
ratings_list = [1, 10, 10, 8, 6]list(zip(movie_list, ratings_list))
- タプルにまとめられたリストが出力できる
リスト内の重複を見つける
- よくある課題の一つに、リスト内で重複する要素を見つけるというのがある
- このアルゴリズムも実際のプログラミングでよく使う
- 解決方法として、リスト内の要素を一つずつ、ほかのすべての要素と比較するやり方がある
- しかし、この処理には二重ループが必要となるため、オーダーが
O(n2)になる
- この場合、ループを使うより
setを使うとよい setは重複する要素を持てないデータ型で、重複する要素の追加は単に無視される- この動作を使って、対象のリストの要素を1つずつ
setに追加していき、setの要素数が変わらなかったらその要素は重複データだ、と判断できる
def return_dups(an_iterable):
dups = []
a_set = set()
for item in an_iterable:
l1 = len(a_set)
a_set.add(item)
l2 = len(a_set)
if l1 == l2:
dups.append(item)
return dups
a_list = ['A', 'B', 'C', 'A']
dups = return_dups(a_list)
print(dups)
# >>> 'A'2つのリストの交差を探す
- よく使うアルゴリズムに、2つのリストの交差を見つけるアルゴリズムがある
- 交差とは、共通する要素のこと
import numpy as np
np.random.seed(6)
list1 = np.random.randint(1,10,5)
list2 = np.random.randint(1,10,5)
print(list1)
print(list2)
# [4 5 1 2 2]
# [5 2 9 3 5]- inと内包表記をつかってリスト内を順に探索する
- この場合、線形探索となりオーダーは
O(n2)となる
def return_inter(list1, list2):
list3 = [v for v in list1 if v in list2]
return list3
return_inter(list1, list2)
# [5, 2, 2]- 違うやり方を考える
- Pythonの
setにはintersectionメソッドがあり、2つのsetで共通する要素を返してくれる listをsetに変換する

setに変換しさえすれば、intersectionメソッドで2つのデータから重複要素を取り出せる- リストに戻す場合は以下でよい

- まとめると以下
def return_inter(list1, list2):
set1 = set(list1)
set2 = set(list2)
return list(set1.intersection(list2))
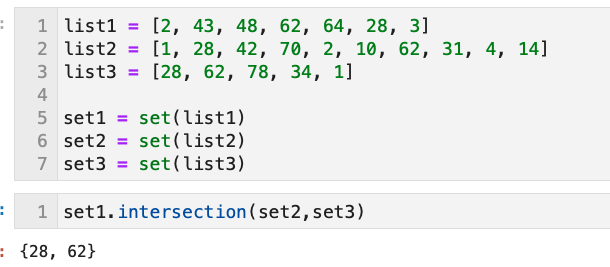
list1 = [2, 43, 48, 62, 64, 28, 3]
list2 = [1, 28, 42, 70, 2, 10, 62, 31, 4, 14]
new_list = return_inter(list1, list2)
print(new_list)
# >>>[2, 28, 62]- また、
intersectionは2つのsetだけなく、複数のsetに対しても利用できる - 以下は3つの
setの共通要素を取り出している(関数にはしてないが)