目次
データ結合の種類
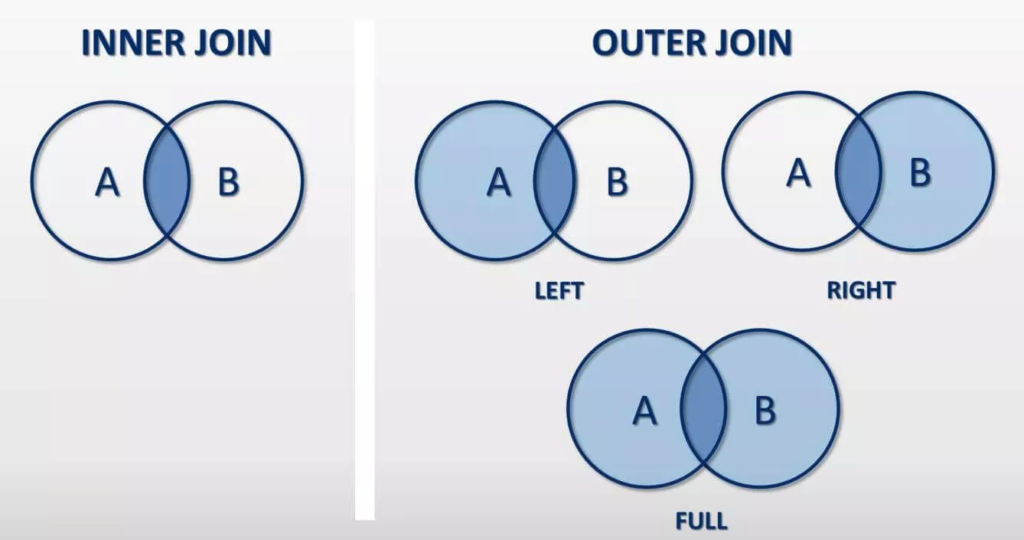
appendは柔軟性なし、新たな行の追加しかできないconcatは DataFrame, Series いずれの軸方向にいくつでも結合できるmergはSQL的に2つのDataFrameをジョインできる
【77】DataFrameに新たな行を追加
- 通常、列(カラム)を作成することが多い
- 新たな行を追加する=データ取得はDB側で管理するのがほとんど
names = pd.DataFrame(
{'Name': ['Cornellia', 'Abbas', 'Penelope', 'Niko'],
'Age': [70, 69, 4, 2]})names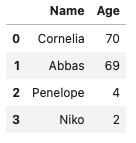
locインデクサ
- locインデクサは元DFをインプレースで書き換えるので注意
# いずれも末尾に行を追加する
new_data_list = ['Aria', 1]
names.loc[4] = new_data_list
names.loc['four'] = ['Zach', 3]
names.loc[len(names)] = {'Name': 'Zayd', 'Age': 2}
# 辞書で追加すると読みやすい(推奨)
names.loc[len(names)] = pd.Series({'Name':'Dean','Age':32})appendメソッド
- append は「行」しか追加できない
- append は元のDF、追加する行のDFのいずれにもインデックスが必要
- 行名なしに追加するには、ignore_index=True が必要、ないとエラーになる
- append を使うと index がリセットされる(RangeIndexで置き換わる)
- 非破壊的(元データは変わらない)
names.append({'Name':'Mao', 'Age':12}, ignore_index=True)
- Seriesで追加すると他のインデックスはそのまま(name=len(names)は必須)
s = pd.Series({'Name':'Mao', 'Age':12}, name=len(names))
names.append(s)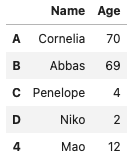
- 同時に複数行を追加できる
s1 = pd.Series({'Name':'Taro', 'Age':13}, name=len(names))
s2 = pd.Series({'Name':'Jiro', 'Age':15}, name=len(names))
s3 = pd.Series({'Name':'YoKo', 'Age':11}, name="G")
names.append([s1,s2,s3])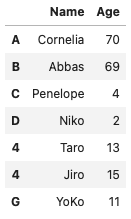
カラム名を書き出す
- カラムが多いと「カラム名: 値」を書き出すのが大変….?そんなときは。
- 辞書を使い、テンプレートとして書き出す事ができる
- isinstance(obj, str or int) はobjがstrまたはintであればTrueを返す

data_dict = bbball_16.iloc[0].to_dict()
print(data_dict)
# {'playerID': 'altuvjo01', 'yearID': 2016, 'stint': 1, 'teamID': 'HOU', 'lgID': 'AL', 'G': 161, 'AB': 640, 'R': 108, 'H': 216, '2B': 42, '3B': 5, 'HR': 24, 'RBI': 96.0, 'SB': 30.0, 'CS': 10.0, 'BB': 60, 'SO': 70.0, 'IBB': 11.0, 'HBP': 7.0, 'SH': 3.0, 'SF': 7.0, 'GIDP': 15.0}
new_data_dict = {k: '' if isinstance(v, str) else \
np.nan for k, v in data_dict.items()}
print(new_data_dict)
# {'playerID': '', 'yearID': nan, 'stint': nan, 'teamID': '', 'lgID': '', 'G': nan, 'AB': nan, 'R': nan, 'H': nan, '2B': nan, '3B': nan, 'HR': nan, 'RBI': nan, 'SB': nan, 'CS': nan, 'BB': nan, 'SO': nan, 'IBB': nan, 'HBP': nan, 'SH': nan, 'SF': nan, 'GIDP': nan}1000行をappendする
- 一行ずつループすると時間がかかる
- まとめて追加する
# 1000行を作成(インデックスも付与)
random_data = []
for i in range(1000):
d = dict()
# data_dict.items()は前述の辞書セット
for k, v in data_dict.items():
if isinstance(v, str):
d[k] = np.random.choice(list('abcde'))
else:
d[k] = np.random.randint(10)
# 最終行の行名をnameで追加
random_data.append(pd.Series(d, name=i + len(bbball_16)))
random_data[0].head()
# playerID b
# yearID 9
# stint 3
# teamID d
# lgID a
# Name: 16, dtype: object
# 一行ずつループしてappendした場合
%%timeit
bbball_16_copy = bbball_16.copy()
for row in random_data:
bbball_16_copy = bbball_16_copy.append(row)
# 5.07 s ± 113 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# まとめてappendした場合
%%timeit
bbball_16_copy = bbball_16.copy()
bbball_16_copy = bbball_16_copy.append(random_data)
# 53.2 ms ± 1.28 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
【78】複数のDataFrameを接合
concat
縦にそのまま連結
- 問題:各行の年を指定する方法がない
stock_2016 = pd.read_csv('stocks_2016.csv', index_col='Symbol')
stock_2017 = pd.read_csv('stocks_2017.csv', index_col='Symbol')
display(stock_2016, stock_2017)
s_list = [stock_2016, stock_2017]
pd.concat(s_list)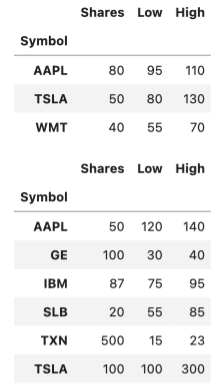
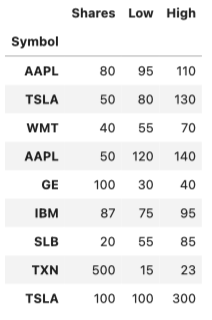
keys(ラベル指定)とMultiIndex
- ラベルを指定する(keysパラメータ)→ MultiIndexになる
- インデックスレベル(namesパラメータ)
- ※ dfって、リストにできるんだ。リストにすればそのままconcatにまとめて突っ込める
s_list = [stock_2016, stock_2017]
pd.concat(s_list, keys=['2016', '2017'], names=['Year', 'Symbol'])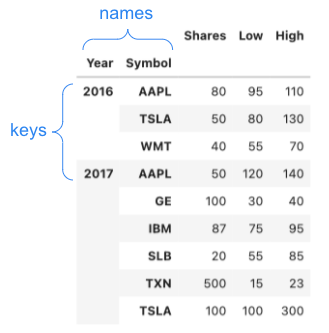
外部ジョイン(Outer Join)
- concat のデフォルトは「外部ジョイン」→全行を保持する
- 片方に値がない場合は欠損値になる
- axisパラメータ:columns or 1で水平方向に連結
pd.concat(s_list, keys=['2016', '2017'], \
axis='columns', names=['Year', None])
# Noneにすると薄青セルが非表示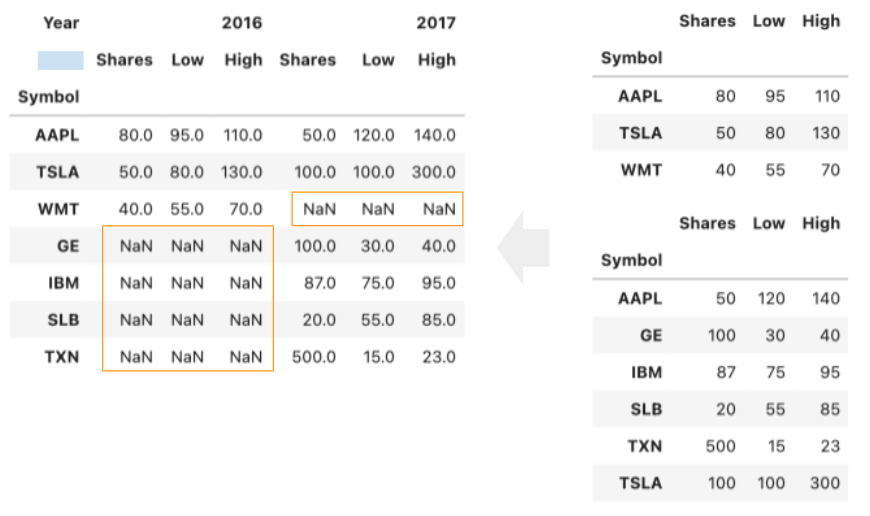
内部ジョイン(Inner Join)
- inner joinの場合、両方のDFに同じインデックスがある行だけを連結する
pd.concat(s_list, join='inner', keys=['2016', '2017'], \
axis='columns', names=['Year', None])
【80】concat,join,mergeの相違点
- concat
- pandas関数
- 複数のpandasオブジェクトを鉛直、水平に結合
- インデックスでのみアライメント
- インデックスに重複があればエラー
- デフォルトは外部ジョイン、オプションで内部ジョイン
- join
- DataFrameメソッド
- 複数のpandasオブジェクトを水平に結合
- 呼び出しDataFrameのカラム/インデックスと他のオブジェクトの(カラムではなく)インデックスとでアライメント
- ジョインするカラム/インデックスの重複は、デカルト積計算で処理
- デフォルトは左ジョインだがオプションで内部、外部、右ジョイン
- merge
- DataFrameメソッド
- 2つのDataFrameだけを水平に結合
- 呼び出しDataFrameのカラム/インデックスと他のDataFrameのカラム/インデックスでアライメント
- ジョインするカラム/インデックスの重複は、デカルト積計算で処理
- デフォルトは内部ジョインだがオプションで左、外部、右ジョイン
concat(default)
# stock_tablesには3つのDFを含む前提(Type:List)
# stock_2016, stock_2017, stock_2018 = stock_tables
pd.concat(stock_tables, keys=[2016,2017,2018])
concat (axis=’columns’)
years = 2016,2017,2018
pd.concat(dict(zip(years, stock_tables)), axis='columns')
# ↑下部を参照。concatに辞書を渡す 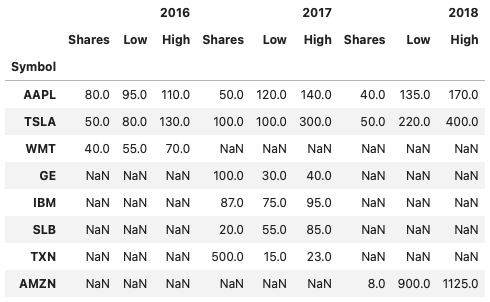
- zipを使えば、dict(辞書形式)でkeyもDataFrameもまとめられる
dict(zip(years, stock_tables))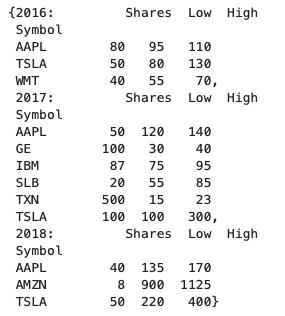
join
- ついでに、カラム名がわかりづらいので
suffixで年を追加する - suffix ・・・接尾語
stock_2016.join(stock_2017, lsuffix='_2016', rsuffix='_2017', how='outer')
suffixは以下の方法でも追加できる
stock_2016.add_suffix('_2016')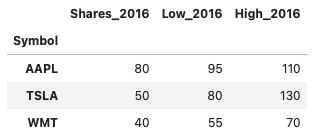
merge
- 2つのDataFrameを結合する
- mergeは同じカラム名でアライメント(整列)する
- Booleanパラメータ left-indexとright-indexをTrueにすればインデックスでアライメントも可能