目次
どんなエラー
- pd.read_csv で CSV を読み込んだときに出るエラー
- 型指定をせずに読み込んだ場合、pandas が勝手に型変換して読む
- その結果、列 2, 12, 14 に複数の「型」が存在した状態になってますよ、というエラー
例
- int, float, str 等が混在している
- 列の一部に「空欄(np.nan)」があった場合、そこは強制的に「NaN」(=float型)に変換されている。その列のほとんどの値が str や int であった場合、それらと float 型が混在してますよ、のエラーになる
- ちなみに「文字列の空欄(str)」の場合、強制的に変換するとNaNになる
対策
- 対象の列を dtype や astype などで適切な値に変換すればよい
# エラー全体は以下のような感じ
DtypeWaring: Columns (2,12,14) have mixed types.Specify dtype option on import or set low_memory=False.どう処理すればよいか?
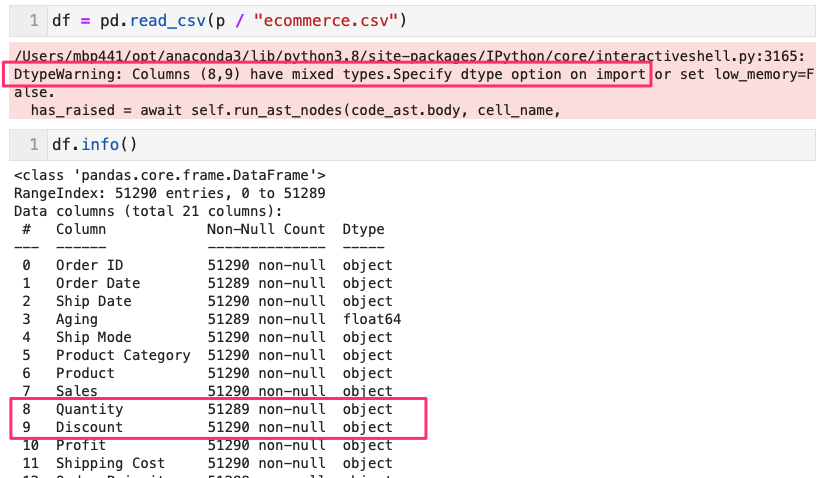
- read_csvすると、以下のMSG
- df.info() で見ると、列8は欠損値がある(1個)
- ただし列9には見た目欠損値はカウントされてない
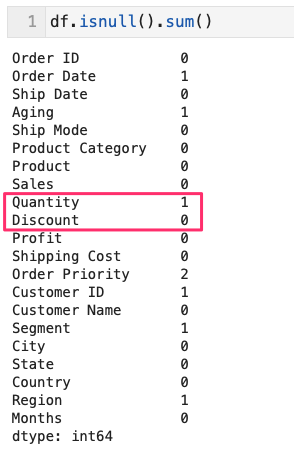
- df.info() でなく、df.isnull().any() で調べても同じ

- df.isnull().sum() のほうが欠損数が出るのでわかりやすい
- 列「Quantity」「Dicount」だけ取り出して、調べていく
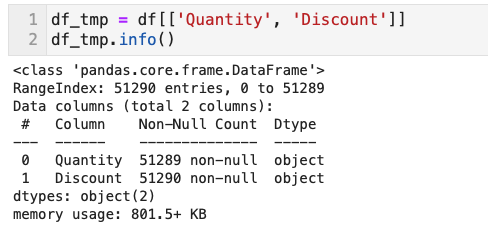
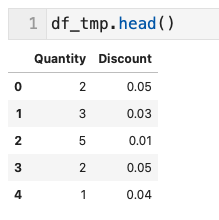
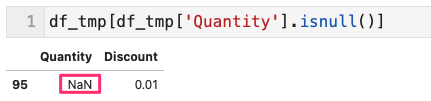
- まず列「Quantity」は欠損値があったので対象行を見てみる
- 他が数値で、列の型が「Object」ってことは、read_csvで取込みした際、「文字としての空欄」箇所が「NaN(str)」に強制変換された。結果、int と str が混在しObject型になった。
- 列 Discount に 欠損値 はないため、もちろんNaNはない
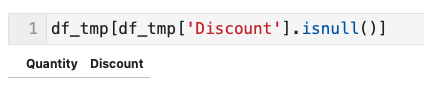
- どうやって列 Discount から混在した文字列を探すか??
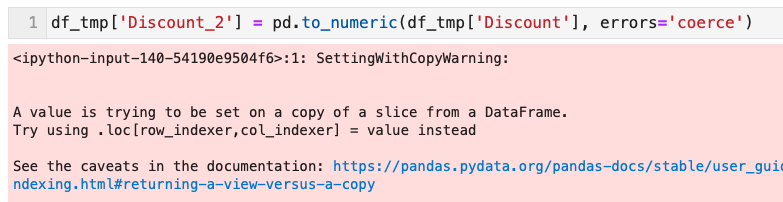
- その場合は、pd.to_numeric で強制的にその列を数値に変換した列を別に作成して比較すればよい
- 強制的に変換した場合、その文字列はNaNになっている
- 元のdfはコピーをとり実施しないと以下のエラーになる)
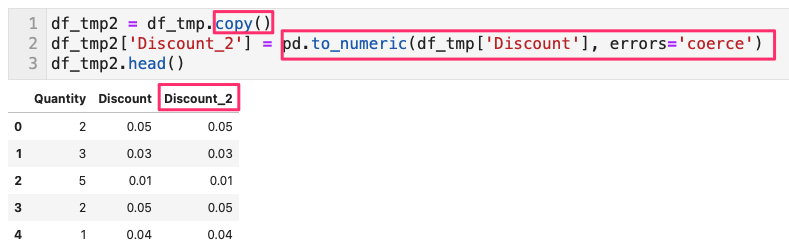
- 新しく作成した列「Discount_2」を利用し、NaNを含む行を探せばよい
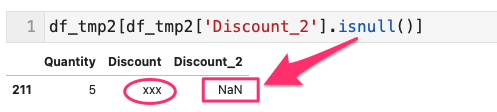
- つまり、列「Discount」に含まれる文字列は xxx であった。
- 以上で数値列に含まれる欠損値ならびに文字列がわかったので、それらの値またはその行自体をどうするかを決めてから、集計作業等に入ることになる
- 例)列「Quantity」のNaN行は削除するのか、別の値に置き換えるのか?
- 例)列「Discount」のxxx 文字列はNaNに強制変換して行ごと除外するのか、別の値に変えるのか?、など。