目次
用語集
- 連結リスト
リストの抽象データ型の実装の一つ - ノード
データ構造の構成要素で、値と次のノード位置をもつ - ポインター
連結リストの次のノード位置をもつ、各ノードの一部 - ヘッド
連結リストの最初のノード - 片方向リスト
連結リストの一種で、次の要素だけを指すポインターをもつリスト - 双方向リスト
連結リストの一種で、各ノードが次のノードを指すポインターと前のノードを指すポインターの2つを持ち、どちらの方向にも移動できるリスト - 循環リスト
連結リストの一種で、最後のノードが最初のノードを指しているので、リストの最後の要素からリストの先頭に戻れるリスト - 循環
連結リストのいずれかのノードが、前のノードを指していること - ランダムアクセス
定数時間内にランダムにデータにアクセスすること
連結リストとは
- 連結リスト
- リスト抽象データ型の実装のひとつ
- 配列と同じように、要素を追削したり、検索もできる
- 配列と異なる点は、連結リストの要素は連結したノードで構成されている
- ノードのメモリーアドレスは連続しておらず、それぞれのノードが値と次のノード位置をもつ
- このため、連結リストの要素にはインデックスがない
- 連結リストの最初のノードをヘッドという。
- 各ノードが持つ次のノード位置のことをポインターとよぶ
- 連結リストの最後のノードのポインターは、多くの場合、Noneを指し、最後の要素だとわかる
- 配列とは異なり、連結リストのノードは連続したメモリーアドレスに格納する必要がない
- リストの要素aの次の要素bは、メモリー上のどこにでも格納できる
- それぞれのノードは、リスト内の次のノードのアドレスへのポインターを持っていて、リストのすべての要素がつながっている
- 連結リストの最初の要素aは、次の要素bのメモリー上の「0x41**」へのポインターをもつ
- このようにポインターを辿ると、リストを構成するすべてのノードの順番が分かるようになっている
- 連結リストに要素を挿入する
- このとき、2つのノードのポインターだけを調整するだけでよく、他のデータの位置を移動する必要はない
- 例)要素a(bへのポインター有り)、要素b(cへのポインターあり)、….
- aとbの間にfを追加するには、要素aの(bへのポインター有り)をc(のメモリーアドレスへの)のポインターに変え、かつfにbへのポインターを追加すればよい
- 他の要素を変える必要はない
- 連結リストの種類
- 片方向リスト
- 次の要素だけを指すポインターを持つ連結リスト
- 移動する場合、ノードを先頭から後ろの方へ移動するしかない
- 双方向リスト
- 各ノードは2つのポインタを持ち、次のノードと前のノードを持つ連結リスト
- これにより双方向リストはどちらの方向にも辿って移動ができる
- 循環リスト
- 最後のノードが最初のノードのポインターを持っている
- リストの最後の要素から最初の要素に移動できる
- 明確な始点と終点をもたないデータを繰返し循環するようなアプリで役に立つ
- なお、連結リストのいずれかのノードが前のノードを指している場合、そのデータ構造は循環を含むいえる
- 片方向リスト
連結リストのパフォーマンス
- 配列の場合、アクセスしたいインデックスがわかっていれば、定数時間でアクセスできる
- しかし、連結リストの要素にアクセスしたい場合は、先頭からその要素まで線形に辿るしか方法がなく、
O(n)の計算量になる
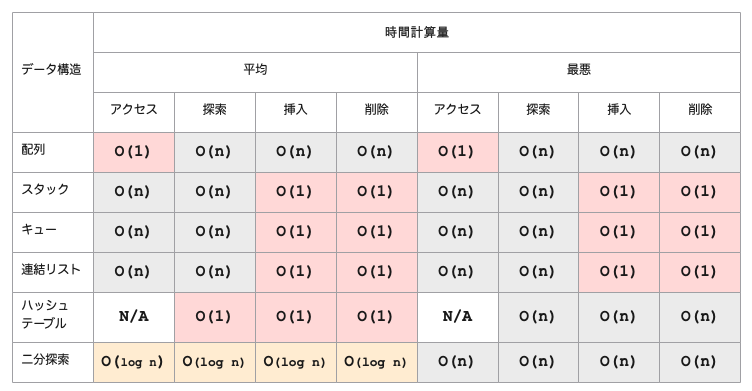
- 一方で、連結リストへのノードの追加(挿入)と削除は、定数時間
O(1)で済む - 逆に配列への要素の追加と削除は
O(n)になる - この違いが、配列ではなく連結リストを使う大きな利点になる
- 連結リストとPython組み込みの
listやarrayは、どれもリスト対象データ型の実装になる - そのため、リスト抽象データ型を使えるあらゆる状況で連結リストを使える
- 前述の通り、データの追削は配列の場合に
O(n)で、連結リストの場合にはO(1)になる - 頻繁にデータを追削するアルゴリズムでは、連結リストの利用を検討すること
- OSのメモリー管理、データベース、会計・財務・販売取引などのシステムでは、連結リストが多用されている
- また、連結リストを使って、ほかのデータ構造をつくることができる
- たとえば、連結リストを使ってスタックとキューがつくれる(後の章でまなぶ)
- 暗号資産などを支えるWeb3を代表するブロックチェーンの技術にも連結リストは必要不可欠
- いくつかの場面で便利な連結リストだが、デメリットもある
- 1つは、各ノードが次のノードへのポインターを持たなければならない点。そのため配列よりもメモリーを必要とする。単純に配列の2倍のメモリーが必要
- 2点目は、ランダムアクセスができない。ランダムアクセスとは、
O(1)でランダムにアクセスできることを指す。 - たとえば、連結リストの先頭から3番目の要素にアクセスするとき、到達するまで各ポインターを追いかけなければならず、配列のように直接アクセスする方法がない
- ただし、この問題を克服したより高度な連結リストもある
連結リストを作成する
- Pythonで連結リストを実装する方法はたくさんある
- その一つは、連結リストとそのノードを表すクラスを定義すること
- 以下はノードを表すクラス定義になる
class Node:
def __init__(self, data, next=None):
self.data = data
self.next = next- 最初のdata変数は1つのデータを持ち、2番目のnext変数はリストの次のノードを持つ
- Pythonは自動でメモリーを管理してくれるため、C言語のようにメモリーアドレスを直接扱う必要はない
- Nodeというクラスのインスタンスを作成すると、Pythonはそのオブジェクトへのポインター(または参照)を返します
- このポインターは、実際のデータが存在するコンピュータのメモリー上のアドレスになる
- Pythonでオブジェクトを変数に代入すると、ポインターを扱います
- そのため、Pythonが基礎的な作業をやってくれるので、オブジェクトを簡単に連結できます
下枠の説明
- 行8
- 次に、連結リストを表すクラスを定義し、リストの先頭を指す head という変数を定義し、リストに新しいノードを追加するメソッドも追加する
- 行10
- appendメソッドは引数としてデータを受け取り、そのデータで新しいノードを作成し連結リストに追加します
class Node:
def __init__(self, data, next=None):
self.data = data
self.next = next
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
return
current = self.head
while current.next:
current = current.next
current.next = Node(data)
def __str__(self):
data_list = []
node = self.head
while node is not None:
data_list.append(node.data)
node = node.next
return "\n".join(data_list)- 行11~13
- リストにまだヘッドがない場合、新しいノードを作成し、それが連結リストのヘッドになる
- 行14
- リストにすでにヘッドがある場合、連結リストの最後のノードを見つけ、新しいノードを作成し、最後のノードのnext変数にあたらしく作ったノードを設定する
- これを実現するために、current 変数を用意して、リストのヘッドを代入する
- 行15
- そして、whileをつかって、current.nextが真のあいだ、ループを継続する
- 行15,16
- while文はcurrentに、current.nextを代入し、current.nextがNoneになるまで(リストの最後に到達するまで)ループを継続する
- 行17
- current変数は、リストの最後のノードをもっているので、新しいノードを作成して、current.nextに代入する
(↓上記と同じスクリプトを記載)
class Node:
def __init__(self, data, next=None):
self.data = data
self.next = next
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
return
current = self.head
while current.next:
current = current.next
current.next = Node(data)
def __str__(self):
data_list = []
node = self.head
while node is not None:
data_list.append(node.data)
node = node.next
return "\n".join(data_list)- 行19
- __str__ メソッドを LinkedList クラスに追加して、リスト内のすべてのノードを簡単に表示できる
- __str__ は Python の「特殊メソッド」
- クラスに __str__ メソッドを定義すると、Python はオブジェクトを表示する際にそのメソッドを呼び出します(print()もこれを呼び出している)
deque()
- ここまで連結リストをPythonで実装してきた
- 実はPythonにも組み込みの「
deque」というデータ構造があり、内部で連結リストを使っている - 組み込みの
dequeデータ構造を利用すると、自分でコーディングしなくても連結リストのパフォーマンスの良さを実感できる
from collections import deque
d = deque()
d.append('A')
d.append('B')
# あまり意味がないコードだな。。。
for item in d:
print(item)
# >>>A
# >>>B連結リストを探索する
- 前の章で紹介したLinkedListクラスのappendメソッドを少し修正すると、連結リスト内の要素を探索できる
class Node:
def __init__(self, data, next=None):
self.data = data
self.next = next
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
return
current = self.head
while current.next:
current = current.next
current.next = Node(data)
def __str__(self):
data_list = []
node = self.head
while node is not None:
data_list.append(node.data)
node = node.next
return "\n".join(data_list)
def search(self, target):
current = self.head
while current:
if current.data == target:
return True
else:
current = current.next
return False- この search メソッドは、検索対象の target 引数を受け取った後、連結リストの要素を繰返し処理し、現在のノードのデータが検索対象と一致したら、True を返す
- 行30
- 現在のノードがデータと一致しない場合は、連結リストの次のノードに current を設定し、繰返し処理を続ける
- 次のコードは、20個の要素が入った連結リストを作成し、その中から10という数字を探索する
import random
a_list = LinkedList()
for i in range(0, 20):
j = random.randint(1, 30)
a_list.append(j)
print(j, end=" ")
print(a_list.search(10))
# >>>1 11 19 19 18 14 14 14 10 25 20 27 12 25 3 22 23 3 24 15 True連結リストからノードを削除する
- 連結リストからノードを削除する方法も技術面接でよく効かれる
- 線形探索を使って連携リスト内のノードを見つけ、削除する
- ノードを削除するためには、前のノードのポインタを変更して、削除したいノードを指さないにする
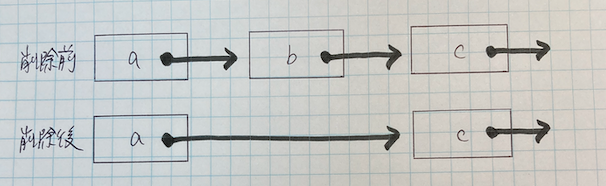
- 連結リストのノードを削除する方法を説明する
class Node:
def __init__(self, data, next=None):
self.data = data
self.next = next
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
return
current = self.head
while current.next:
current = current.next
current.next = Node(data)
def __str__(self):
data_list = []
node = self.head
while node is not None:
data_list.append(node.data)
node = node.next
return "\n".join(data_list)
def search(self, target):
current = self.head
while current:
if current.data == target:
return True
else:
current = current.next
return False
# 連結リストのノードを削除する
def remove(self, target):
if self.head.data == target:
self.head = self.head.next
return
current = self.head
previous = None
while current:
if current.data == target:
previous.next = current.next
previous = current
current = current.next- 行37
- 削除したいノードがリストの先頭だった場合の処理
- もし先頭だったら、self.headに次(next)のノードを設定し終了
- 行41
- 先頭でない場合、連結リストの要素を繰返し処理し、
- 現在(current)のノードと直前(previous)のノードを格納
- 行43
- 連結リストの要素を繰返し処理する
- 探しているデータが見つかったら、previous.nextにcurrent.nextを代入し、連結リストからそのノードを削除する
連結リストを逆順にする
- 連結リストを逆順にするには、現在のノードと前のノードの両方を追跡しながら繰返し処理する
- そして、現在のノードが前のノードを指すようにする
- 連結リストのすべてのポインターを変更したら、逆順になる
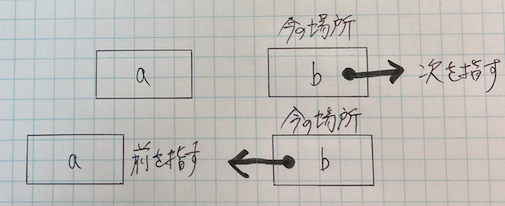
class Node:
def __init__(self, data, next=None):
self.data = data # Nodeは、1番目のdata変数にデータをもち
self.next = next # 2番目のnext変数はリストの次のノードを持つ
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
return
current = self.head
while current.next:
current = current.next
current.next = Node(data)
def __str__(self):
data_list = []
node = self.head
while node is not None:
data_list.append(node.data)
node = node.next
return "\n".join(data_list)
def search(self, target):
current = self.head
while current:
if current.data == target:
return True
else:
current = current.next
return False
def remove(self, target):
if self.head.data == target:
self.head = self.head.next
return
current = self.head
previous = None
while current:
if current.data == target:
previous.next = current.next
previous = current
current = current.next
def reverse_list(self):
current = self.head
previous = None
while current:
next = current.next
current.next = previous
previous = current
current = next
self.head = previous- 行52
- while の中で current.next を next 変数に代入してから、次の行において current.next に previous を代入する
- current.next を previous に設定すれば、そのノードのポインターを逆転させたことになる
- 行54
- すべてのポインターを変更したら、self.head に previous を設定する
- 連結リストの最後まで到達すると、current は None になり、previous には連結リストの最後ののーどが格納されているので、これをリストの先頭に設定すれば最初のノードになるからです
連結リストの循環を見つける
- 冒頭で、循環リストでは最後の要素がリストの先頭を指すと説明した
- 技術面接でよく問われるのは、連結リストが循環を含んでいるか否かを検出する方法についてです
- つまり、リストの最後の要素が、next 変数の値として None を持つ代わりに、リスト内の任意の要素を指しているかどうかチェックします
- 連結リストの循環を検出するアルゴリズムの1つは、ウサギとカメのアルゴリズムと呼ばれています
- このアルゴリズムでは、連結リストを2つの異なる速度で繰返し、ノードを slow と fast という変数に格納する
- 連結リストが循環していれば、最終的には fast が slow に追いつき、両方の変数が同じになります。
- もしそうなれば、連結リストが循環していることがわかります
- 何も起こらずに連結リストの末尾に到達した場合、そのリストには循環が含まれていないことがわかります
- 以下は、ウサギとカメのアルゴリズムの実装例です
class Node:
def __init__(self, data, next=None):
self.data = data
self.next = next
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
return
current = self.head
while current.next:
current = current.next
current.next = Node(data)
def __str__(self):
data_list = []
node = self.head
while node is not None:
data_list.append(node.data)
node = node.next
return "\n".join(data_list)
def search(self, target):
current = self.head
while current:
if current.data == target:
return True
else:
current = current.next
return False
def remove(self, target):
if self.head.data == target:
self.head = self.head.next
return
current = self.head
previous = None
while current:
if current.data == target:
previous.next = current.next
previous = current
current = current.next
def reverse_list(self):
current = self.head
previous = None
while current:
next = current.next
current.next = previous
previous = current
current = next
self.head = previous
def detect_cycle(self):
slow = self.head
fast = self.head
while True:
try:
slow = slow.next
fast = fast.next.next
if slow is fast:
return True
except:
return False行58〜説明
- まずは fast と slow の2つの変数からはじめる
- そして無限ループを作る
- 無限ループの中では、連結リストの次のノードを slow に、その次のノードを fast に割り当てる
- このコードを try ブロック内に記述したのは、連結リストに循環が含まれない場合、最終的に fast は None となって None に対して fast.next.next を呼び出すことになり、これがエラーを起こすからです
- また try ブロックは、入力が空のリストや、1つだけの要素の非循環のリストである場合に、プログラムの失敗を回避する
- 次に slow と fast が同じ object であるかどうかをチェックします
- 同じ値が複数のノードに現れる可能性があるため、2つの連結リストのノードの値が同じかどうかはチェックしません。
- その代わりに is キーワード を使って、2つのノードが同じオブジェクト弟あるかどうかをチェックします
- もしそれらが同じオブジェクトであれば連結リストは循環していることになるので、True を返す
- エラーが発生した場合、.next.next を None に対して呼び出したとことになります。つまり、連結リストは循環していないのでFalseを返します
訳注コラム:例外処理をうまく扱う
# 行58以降は以下より下部のほうがよい
def detect_cycle(self):
slow = self.head
fast = self.head
while True:
try: # 例外捕捉対象ではないコードが含まれる
slow = slow.next
fast = fast.next.next
if slow is fast:
return True
except: # 例外指定がなく想定外の例外まで捕捉する
return False
def detect_cycle(self):
slow = self.head
fast = self.head
while True:
try: # try節には例外捕捉対象の処理だけを書く
slow = slow.next
fast = fast.next.next
except AttributeError: # 例外の種類を指定する
return False
if slow is fast: # 例外捕捉の対象としない
return True