目次
オプション一覧
| No | オプション | 使用例 | 説明 |
| 1 | io | ||
| 2 | sheet_name | sheet_name=0 1番目のシート1(default) sheet_name=1 2番目のシート sheet_name=’Sheet1′ sheet_name=[0, 1, ‘Sheet5’] sheet_name=None すべてのワークシート | 読み込むシート名 |
| 3 | header | デフォルトで1行目がヘッダーになる header=None ヘッダーなし header=1 2行目をヘッダー header=[0,1] 1-2行目をMultiIndexにする ※headerに指定されたX行が一番上の行になり、X行より上の行はスキップされる | ヘッダー(カラム)を 既存の行から指定する |
| 4 | names | header=Noneを忘れると1行目が上書きされる names=[‘col_A’, ‘col_B’, ‘col_C’] ヘッダーの名前の意 | ヘッダーを新しく設定 |
| 5 | index_col | ||
| 6 | usecols | usecols=[0,1] 列番号で指定(1列、2列目) usecols=’A,C:E’ Excelの列名で指定(Notリスト) usecols=[‘col_A’, ‘col_C’] hederの列名を指定 | 列を指定して読み込む |
| 7 | squeeze | ||
| 8 | dtype | str、float、str以外の具体的な型を指定する場合は’int8’の文字列で指定する ①dtype=str ②dtype={‘col_A’: str, ‘col_B’: int, ‘col_C’: ‘int8’} | 型を指定して読み込む |
| 9 | engine | ||
| 10 | converters | ||
| 11 | true_values | ||
| 12 | skiprows | skiprows=2 先頭から2行分をスキップ(読み込まない) skiprows=[1, 3] 指定した行番号をスキップする | 読み込まない行を指定する |
| 13 | nrows | nrows=2 指定した行数分を読み込む | 指定した行数分を読み込む |
| 14 | na_values | ||
| 15 | keep_default_na | ||
| 16 | na_filter | ||
| 17 | verbose | ||
| 18 | parse_dates | parse_dates=[0, 2] 列番0, 2をdatetime形式で読み込む | 列をdatetime形式で読み込む |
| 19 | date_parser | ||
| 20 | thousands | thousands=’,’ カンマを除去してintとして読み込む (Excelでテキストとして保存されている場合) | 桁区切りを除去しintで読み込む |
| 21 | decimal | ||
| 22 | comment | ||
| 23 | skipfooter | skipfooter=4 下から4行分をスキップする(読み込まない) | 下からN行分を読み込まない |
オプションなし
# 基本。複数シートがあってもデフォルトのSheet1だけが読み込まれる
# ヘッダーを指定しないと1行目がヘッダーになる
pd.read_excel('test.xlsx')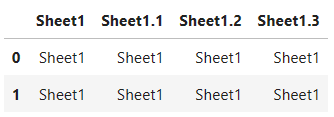
pd.read_excel(
'test.xlsx',
header=None)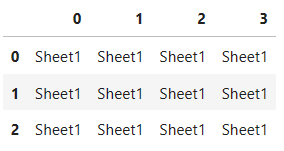
sheet_name
# sheet_name=1は2番目のシートを指す
pd.read_excel(
'test.xlsx',
header=None,
sheet_name=1)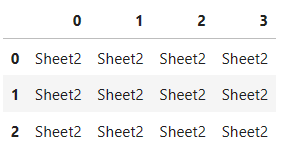
# 複数シートを読み込む場合
df =pd.read_excel(
'test.xlsx',
header=None,
sheet_name=[0,1])
df
display(
df[0],
df[1])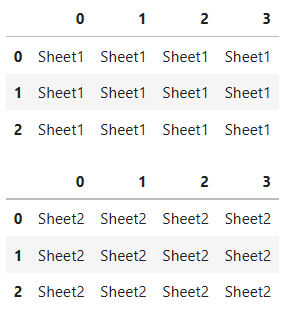
# すべてのシートを読み込む場合は、sheet_name=None
df = pd.read_excel(
'test.xlsx',
header=None,
sheet_name=None)
display(df)
print(f'{len(df)=}')
header
# header:int, list of int, default 0
# default 0
df1 = pd.read_excel(
'test2.xlsx')
# 2行目を指定
df2 = pd.read_excel(
'test2.xlsx',
header=1)
# 複数行を指定
df3 = pd.read_excel(
'test2.xlsx',
header=[0,1])
display(df1,df2,df3)
names
# names: ヘッダーのカラム名をリストで指定する。ただし、header=Noneを指定しないと1行目がヘッダーになり、上書きすることになる
pd.read_excel(
'test2.xlsx',
names=['COL_A', 'COL_B', 'COL_C', 'COL_D'])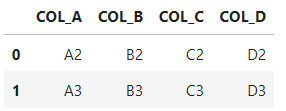
# header=Noneを指定した上で、namesを使うこと
pd.read_excel(
'test2.xlsx',
header=None,
names=['COL_A', 'COL_B', 'COL_C', 'COL_D'])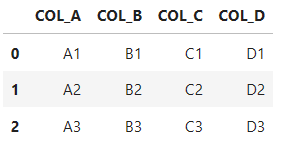
usecols
# usecols: str, list-like, callable, default None
# 列番号で指定(1列目、2列目)
pd.read_excel(
'test2.xlsx',
header=None,
usecols=[0,1])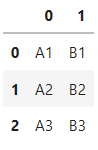
# Excelの列名ABCDなどで指定する場合はリストではなく、strで。
pd.read_excel(
'test2.xlsx',
header=None,
usecols='A,C:D')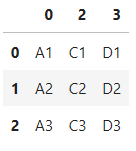
# headerの列名をそのまま指定
pd.read_excel(
'test3.xlsx',
usecols=['col_A', 'col_C'])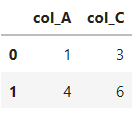
dtype
元データ
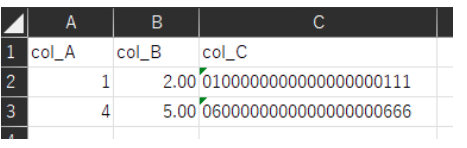
# そのまま読み込んだ場合、1行目の文字列がヘッダーになってしまうため、全部オブジェクトになる
df = pd.read_excel(
'test3.xlsx',
header=None)
display(df)
df.info()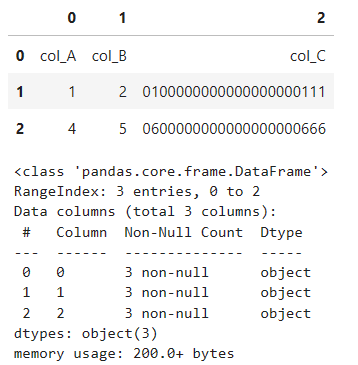
# 1行目のheaderを指定したら、自動で読み取ってくれる。がB列がintになってしまっている
df = pd.read_excel(
'test3.xlsx',
header=0)
display(df)
print(df.info())
# 型を指定して読み込む。型は文字列で表現する(float,strはなしでもよい)
df = pd.read_excel(
'test3.xlsx',
header=0,
dtype={'col_A': 'int8', 'col_B':float, 'col_C': str})
display(df)
print(df.info())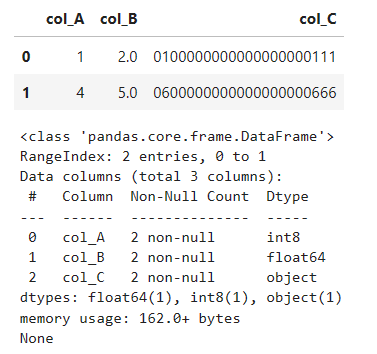
skiprows
# skiprows: list-like, int, or callable, optional
# 2つ行をスキップして読み込む(行数をint指定)
bf = pd.read_excel('test4.xlsx', header=None)
af =pd.read_excel(
'test4.xlsx',
header=None,
skiprows=2)
display(bf, af)
# 指定した行番号をスキップもできる(リスト)
pd.read_excel(
'test4.xlsx',
header=None,
skiprows=[1,3])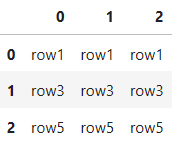
nrows
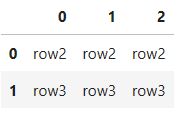
# 指定した行数分を読み込む(1行をスキップした後から2行読み込む)
pd.read_excel(
'test4.xlsx',
header=None,
skiprows=1,
nrows=2
)
parse_dates
元データ
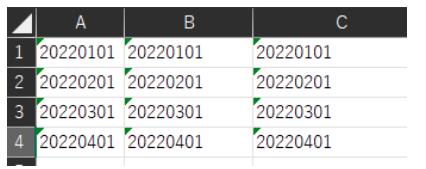
# そのまま読み込んでもintで読み込まれる
df = pd.read_excel(
'test5.xlsx',
header=None)
display(df)
df.info()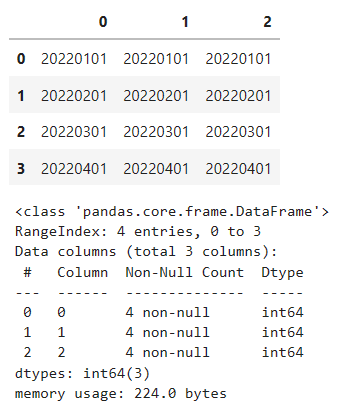
# parse_datesで列0,2をdatetimeで読み込む
df = pd.read_excel(
'test5.xlsx',
header=None,
parse_dates=[0,2])
display(df)
df.info()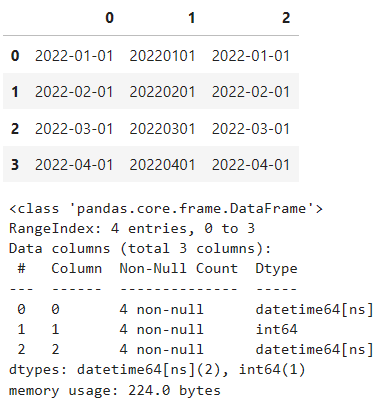
thousands
元データ
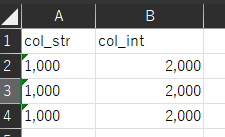
# Excel上で桁区切りがついた文字列で保存されている場合
# そのまま読み込むと、1列目はstrのまま。計算できない。
df = pd.read_excel(
'test6.xlsx',
header=0)
display(df)
df.info()
# thousand=','とするとintになる
df = pd.read_excel(
'test6.xlsx',
header=0,
thousands=',')
display(df)
df.info()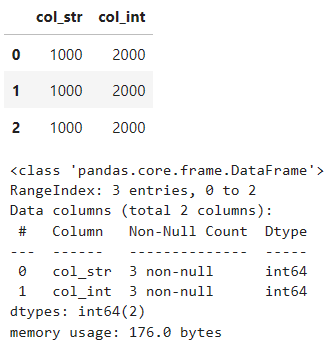
# 下から4行分をスキップする
bf = pd.read_excel('test4.xlsx', header=None)
af = pd.read_excel(
'test4.xlsx',
header=None,
skipfooter=4)
display(bf, af)