辞書を作成
基本
{'col_A': 1, 'col_B': 2, 'col_C': 3}
dict(col_A=1, col_B=2, col_C=3)
dict(zip(['col_A', 'col_B', 'col_C'], [1, 2, 3]))
# dictを使わず、内包表記を利用
{ col: v for col, v in zip(['col_A', 'col_B', 'col_C'], [1, 2, 3]) }
>> {'col_A': 1, 'col_B': 2, 'col_C': 3}
{'col_A': [1, 2, 3], 'col_B': [4, 5, 6], 'col_C': [7, 8, 9]}
dict(col_A=[1, 2, 3], col_B=[4, 5, 6], col_C=[7, 8, 9])
dict(zip(['col_A', 'col_B', 'col_C'], [[1, 2, 3], [4, 5, 6], [7, 8, 9]]))
{col: v for col, v in zip(['col_A', 'col_B', 'col_C'], [[1, 2, 3], [4, 5, 6], [7, 8, 9]])}
>> {'col_A': [1, 2, 3], 'col_B': [4, 5, 6], 'col_C': [7, 8, 9]}
応用
list_1 = ['col_' + s for s in list('ABC')]
list_2 = [i for i in range(3)]
d = {k: v for k, v in zip(list_1, list_2)}
d
>> {'col_A': 0, 'col_B': 1, 'col_C': 2}
DataFrameを作成
- DataFrameはリストまたは辞書から作ることができる(ndarayやseriesはいったん除く)
# リストから
pd.DataFrame(
data = [1,2,3,4]
)
pd.DataFrame(
data = zip(
[1,2,3,4],
[5,6,7,8])
)
# dictから
pd.DataFrame(
data = {'col_A': [1,2,3,4]}
)
pd.DataFrame(
data = {'col_A': [1,2,3,4],
'col_B': [5,6,7,8]}
)
pd.DataFrame(
data = {'col_A': [1, 2, 3, 4],
'col_B': [5, 6, 7, 8],
'col_C': [9, 0, 1, 2]
})
| col_A | col_B | col_C |
|---|
| 0 | 1 | 5 | 9 |
|---|
| 1 | 2 | 6 | 0 |
|---|
| 2 | 3 | 7 | 1 |
|---|
| 3 | 4 | 8 | 2 |
|---|
pd.DataFrame(
data = [
{'col_A': 1, 'col_B': 5, 'col_C': 9},
{'col_A': 2, 'col_B': 6, 'col_C': 0},
{'col_A': 3, 'col_B': 7, 'col_C': 1},
{'col_A': 4, 'col_B': 8, 'col_C': 2},
])
| col_A | col_B | col_C |
|---|
| 0 | 1 | 5 | 9 |
|---|
| 1 | 2 | 6 | 0 |
|---|
| 2 | 3 | 7 | 1 |
|---|
| 3 | 4 | 8 | 2 |
|---|
DataFrameのサンプル作成
import numpy as np
import pandas as pd
import random
np.random.seed(1)
np.random.randint(1, 11, (5, 3))
>> array([[ 6, 9, 10],
[ 6, 1, 1],
[ 2, 8, 7],
[10, 3, 5],
[ 6, 3, 5]])
np.random.seed(1)
data = np.random.randint(1, 11, (5, 3))
pd.DataFrame(
data = data,
columns = list('ABC')
)
| A | B | C |
|---|
| 0 | 6 | 9 | 10 |
|---|
| 1 | 6 | 1 | 1 |
|---|
| 2 | 2 | 8 | 7 |
|---|
| 3 | 10 | 3 | 5 |
|---|
| 4 | 6 | 3 | 5 |
|---|
data = np.arange(15).reshape(5,3)
pd.DataFrame(
data = data,
columns = list('ABC')
)
| A | B | C |
|---|
| 0 | 0 | 1 | 2 |
|---|
| 1 | 3 | 4 | 5 |
|---|
| 2 | 6 | 7 | 8 |
|---|
| 3 | 9 | 10 | 11 |
|---|
| 4 | 12 | 13 | 14 |
|---|
CSV⇔df⇔dict
サンプル df 作成
# サンプルのデータをつくりましょう、となったら(上をならって)
df = pd.DataFrame(np.random.randint(1, 11, (5, 3)), columns = list('ABC'))
df
| A | B | C |
|---|
| 0 | 1 | 2 | 9 |
|---|
| 1 | 9 | 4 | 10 |
|---|
| 2 | 9 | 8 | 4 |
|---|
| 3 | 7 | 6 | 2 |
|---|
| 4 | 10 | 4 | 5 |
|---|
df → dict 変換(辞書へ)★
- to_dict による辞書への変換はよく使う
- 出力する辞書の形式をどうするか、で複数パターンあり(後述)
# dfをdictへ変換するには
a_dict = df.to_dict()
a_dict
>>
{'A': {0: 3, 1: 8, 2: 8, 3: 10, 4: 7},
'B': {0: 5, 1: 10, 2: 1, 3: 10, 4: 10},
'C': {0: 8, 1: 2, 2: 7, 3: 8, 4: 2}}
dict → df 変換
# dictをdfに変換するには
pd.DataFrame(a_dict)
| A | B | C |
|---|
| 0 | 3 | 5 | 8 |
|---|
| 1 | 8 | 10 | 2 |
|---|
| 2 | 8 | 1 | 7 |
|---|
| 3 | 10 | 10 | 8 |
|---|
| 4 | 7 | 10 | 2 |
|---|
df → csv 出力
# dfをCSVへ出力するには
df.to_csv('test.csv', index=False)

csv → df 読み込み
# csvをpandas経由で読み出すと。まんま。
pd.read_csv('test.csv')
| A | B | C |
|---|
| 0 | 3 | 5 | 8 |
|---|
| 1 | 8 | 10 | 2 |
|---|
| 2 | 8 | 1 | 7 |
|---|
| 3 | 10 | 10 | 8 |
|---|
| 4 | 7 | 10 | 2 |
|---|
# 非構造なCSVをpanadaで読むと
with open('test.csv', 'r') as f:
robj = csv.reader(f)
df = pd.DataFrame(robj)
df
| 0 | 1 | 2 |
|---|
| 0 | A | B | C |
|---|
| 1 | 3 | 5 | 8 |
|---|
| 2 | 8 | 10 | 2 |
|---|
| 3 | 8 | 1 | 7 |
|---|
| 4 | 10 | 10 | 8 |
|---|
| 5 | 7 | 10 | 2 |
|---|
# dictにしたいなら
df.to_dict()
>>
{'A': {0: 1, 1: 9, 2: 9, 3: 7, 4: 10},
'B': {0: 2, 1: 4, 2: 8, 3: 6, 4: 4},
'C': {0: 9, 1: 10, 2: 4, 3: 2, 4: 5}}
df. to_dict (~=~ ) ★
- DataFrameを辞書に変換する。出力する辞書の形式は様々
- 現時点、よく使うと思われるものは⑥かな。
① orient=’dict’
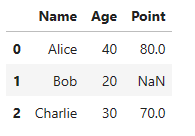 df
df
 orient=’dict’
orient=’dict’
② orient=’list’
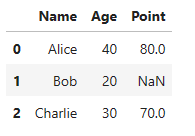 df
df
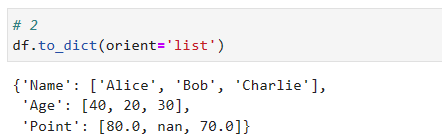 orient=’list’
orient=’list’
③ orient=’series’
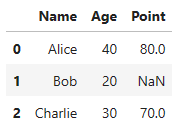 df
df
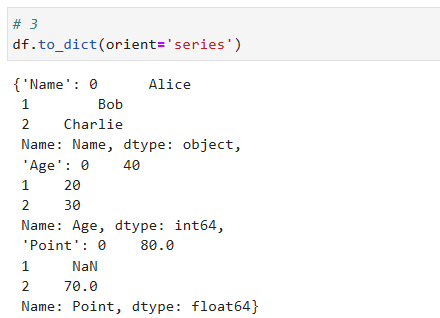 orient=’series’
orient=’series’
④ orient=’split’
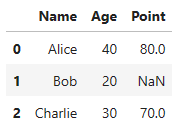 df
df
 orient=’split’
orient=’split’
⑤ orient=’records’
 df
df
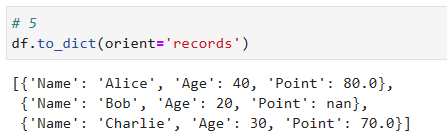 orient=’records’
orient=’records’
⑥orient=’index’
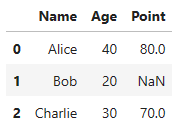 df
df
 orient=’index’
orient=’index’
⑦ into=OrderedDict
- from collections import OrderedDict が必要
- into=の後はクォーテーションは不要
- 順序を保持する(Pyhon3.7以降は通常のdictも保持されるが)
- これは辞書ではない。辞書のサブクラスになる
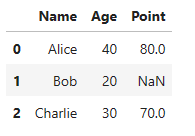 df
df
 orient=’index’, index=OrderedDict
orient=’index’, index=OrderedDict
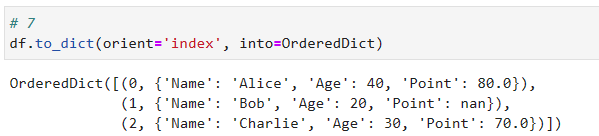
df > 辞書 > 複数の値を同時に取り出す場合
- よく使うと思われるのがこのやり方(実際はもっと良いやり方があるかも)
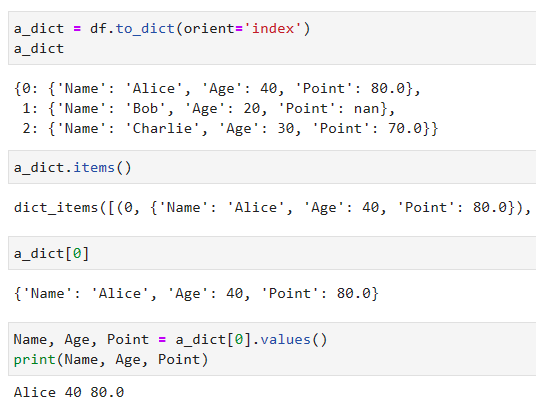 case of dict
case of dict
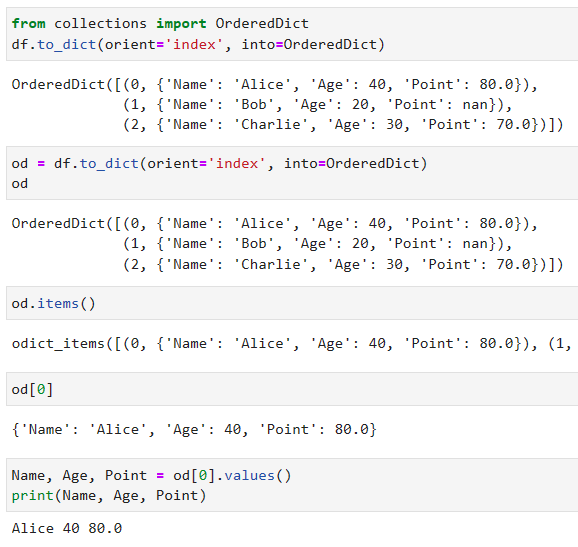 case of OrderedDict
case of OrderedDict
# 関数にするとこんな感じ
def get_values_of_dict(No):
for dict in a_dict.items(): # items()が必要
Name, Age, Point = dict[No].values()
return (Name, Age, Point)
Name, Age, Point = get_values_of_dict(1)
print(Name, Age, Point)
>> Alice 40 80.0
JSON
- JSONファイルはただの「デーフォーマット」のため、辞書のように直接アクセスはできない
- 言語に応じて適切なデータ型に変換して初めてアクセスできる(Pythonの場合は辞書型)
- それが
import json であり、読み込みのjson.loads、書き出しの json.dumps になる
- リストや辞書形式で書き出す場合、そのままではファイルに保存ができない
- そのため、JSON形式で保存する(シリアライズ)