メモ:
TODO: Seriesに対して桁区切りとかはできるのか?
# %の列を追加
df['件数_%'] = df['顧客コード'] / df['顧客コード'].sum()
# 列名を変更
df.rename(columns={'顧客コード':'件数'}, inplace=True)
# 表記を%へ
df.style.format({'件数': '{:,}', '売上': '{:,}', '件数_%': '{:.1%}'})
目次
まとめ
型はそのまま、見た目だけ変える(style)
- df.style.ビルトイン
- df.style.applymap(fn)
- df.style.apply(fn)
- df.style.format()
型そのものを変える
- df.applymap(fn)
- df.apply(fn)
参考HP:pandas-テーブルの表示をカスタマイズする方法
基本形
‘{:〜}’.format()
# 3桁区切り
'{:,}'.format(1234567)
# >'1,234,567'# 小数点2桁(丸まり方に一応注意)
'{:.2f}'.format(1234567.89012)
# >'1234567.89'# 3桁区切り & 小数点2桁
'{:,.2f}'.format(1234567.89012)
# >'1,234,567.89'型はそのまま、見た目だけ変える(style)
# サンプルDF作成
import numpy as np
import pandas as pd
df = pd.DataFrame([[11, None, 15, 4, 5],[2000, 12, 10, 8, 16],
[17, 2400, 14, 13.4589, 23],[19, 6, 1800, None, 7],[3, 9, 20, 21, 1001.125],],
index=["a", "b", "c", "d", "e"],
columns=["A", "B", "C", "D", "E"])
df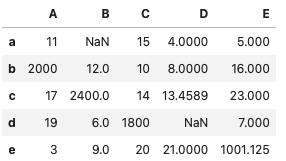
df.style.format()
- これが使いやすい!
# すべてintまたはfloatであれば、全体へ1つの型を適用できる
df.style.format('{:,}') # 3桁区切り
df.style.format('{:.2f}') # 小数点2位(丸まり方は注意)
# ただし、複数の型が混在すると個別の適用はできない(以下図)
df.style.format('{:,.2f}')すべてint・float型であれば
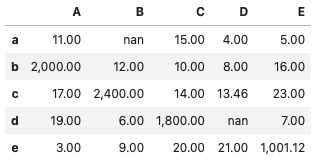
文字列が含まれる場合
# 以下DFの場合、文字列が含まれるため上記の方法ではエラーになる
df = pd.DataFrame([['みかん',1100,1200.0526],
['りんご',2100,-22000.02568]], columns = ["くだもの", "列B", "列C"])
# 列ごとにフォーマットを適用すれば可能
df.style.format({'列B': '{:,}', '列C': '{:,.1f}'})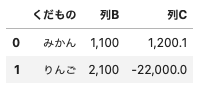
文字列を含む & 列が多い場合
- df.select_dtypes(include={int}).columns でint型のカラム名を取り出す
- include={int, float} と複数指定も可能
- 以下では関数にしている
def style(df):
d = {}
for c_name in df.select_dtypes(include={int}).columns:
d[c_name] = '{:,}'
for c_name in df.select_dtypes(include={float}).columns:
d[c_name] = '{:,.2f}'
print(d)
style = (
df.style.format(d)
.highlight_null()) # + NaN強調
return style
style(df)
df.style.ビルトイン
欠損値を強調
df.style.highlight_null()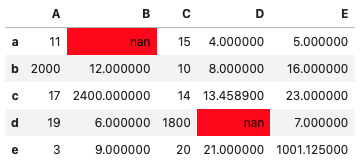
df.style.highlight_null(null_color='yellow')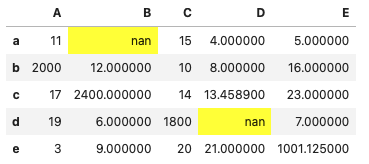
複数の変更を適用する
# 複数の変更を適用する場合は、メソッドチェーンにて.
style = (
df.style.highlight_null(null_color='yellow')
.highlight_min(color="pink")
.highlight_max(color="lime")
)
style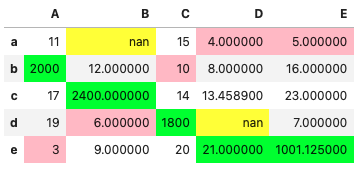
列ごとに最小値を強調
#デフォルトでは列で適用する
df.style.highlight_min(color='pink')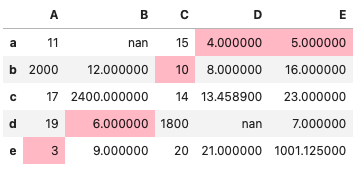
行ごとに最小値を強調
# 適用を行にした場合(axis=1)
df.style.highlight_min(color='pink', axis=1)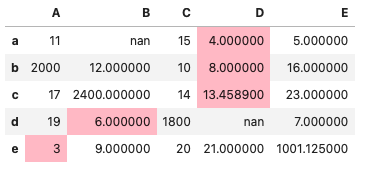
特定の列のみに適用する
# デフォルトでは列で適用する(列B、Eのみ)
df.style.highlight_min(color='pink', subset=['B','E'])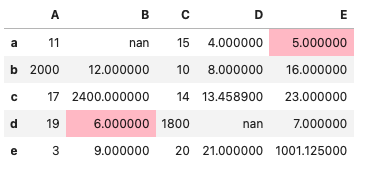
その他のビルトイン
https://pandas.pydata.org/pandas-docs/stable/reference/style.html#builtin-styles

df.style.applymap(fn)
df.style.applymap(fn)- 戻り値:「
color:〜」(CSS) - 各要素の値だけで判断できる場合は
applymap()を利用する - 例)値が60点未満かどうか、セルがnullかどうか、など
- スタイル関数の参照先:要素
サンプルデータ作成
data = {
'Aさん':[75,55,80,90],
'Bさん':[80,80,90,30],
'Cさん':[95,70,85,70],
}
df = pd.DataFrame(data, index = ['国語','数学','理科','社会'])
df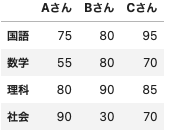
赤点を赤文字で表示
def akaten(val):
color = 'red' if val < 60 else 'black'
return f'color: {color}'
# dfにスタイル適用
df.style.applymap(akaten)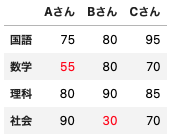
欠損値のセル文字と背景を変更
# NaNのセル文字列・背景色を変更
df2 = df
df2.iloc[1,2] = np.nan
def fill_nan(val):
bg_color = 'silver' if pd.isnull(val) else 'None'
color = 'white' if pd.isnull(val) else 'black'
return f'background-color: {bg_color}; color:{color}'
df2.style.applymap(fill_nan)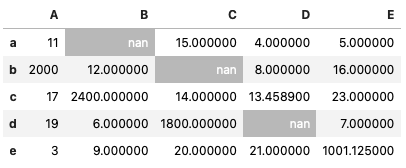
マイナス値の文字色を変更
def color_nagative(v, color):
return f'color: {color};' if v < 0 else None
df3 = pd.DataFrame(np.random.randn(3,3), columns=list('ABC'))
df3.style.applymap(color_nagative, color='red')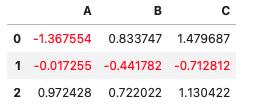
特定の列のみに適用する2
df3.style.applymap(color_nagative, color='red', subset=['A', 'C'])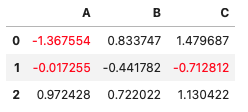
他の事例
def is4(val):
if val == 4:
bg_color = 'red'
color = 'white'
return f'background-color:{bg_color}; color:{color}'
else:
pass
df.style.applymap(is4)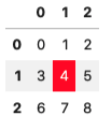
df.style.apply(fn)
df.style.apply(fn)- 戻り値:「color:〜」(CSS)
- 他の要素も含めて判断する必要がある場合は
apply()を利用する - 例)全ての行で一番大きい値の背景色を変える、dfの最大値、など
- スタイル関数の参照先:行、列、DF
サンプルデータ作成
df4 = pd.DataFrame(np.random.randn(3,3), columns=list('ABC'))
def highlight_max(x, color):
return np.where(x == np.nanmax(x.to_numpy()),
f'color: {color};', None)
df4.style.apply(highlight_max, color='red')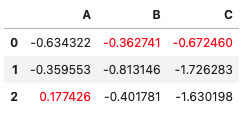
最大値を赤文字に変更
df5 = pd.DataFrame(np.random.randn(3,3), columns=list('ABC'))
def highlight_max(x, color):
return np.where(x == np.nanmax(x.to_numpy()),
f'color: {color};', None)
df5.style.apply(highlight_max, color='red')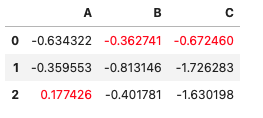
スタイルをクリアする
style = df.style.background_gradient()
display(style)
style.clear()