目次
pd.isin()、todict()、all()を利用すれば出力可能
- df1.isin(df2)としてしまうと、同じ行列であれば突合可能(=compare)
- しかし、2つのDFの行数や列数(行名、列名)が違うと全く違う結果になるので取り扱い注意
- よって、ここでは列をリストにしてまとめてisinに渡すやり方で処理している
- df1に対し、df2をぶつけているので、結果はdf1をベースに出力される
- この場合、df2にだけある行は抽出しないため、必要であれば逆でもあててみるとよい
df1[~df1.isin(df2.to_dict(orient='list')).all(1)]
isin
サンプル作成
df = pd.DataFrame({'num_legs': [8, 4, 6], 'num_wings': [0, 2, 4]},
index=['spider', 'falcon', 'bee'])
df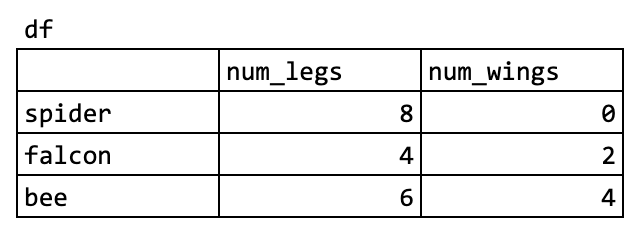
df.isin( list )
- dfにリストの値[0, 4]のいずれかが含まれるか?
df.isin([0, 4])
df.isin( dict )
- dfに辞書が渡された場合、カラム名「num_legs」がdfと同じ列かつ、その列の値に「6,8」のいずれかが含まれるかどうか?
df.isin({'num_legs': [6, 8]})
df.isin( DataFrame, Series )
- DataFrameが渡された場合は、そのDFと同じ列、同じインデックスにおいて、セルの値が同じかどうかを1対1で調べる
other = pd.DataFrame({'num_legs': [8, 2, 6], 'num_wings': [0, 2, 4]},
index=['spider', 'falcon', 'bee_2'])
df.isin(other)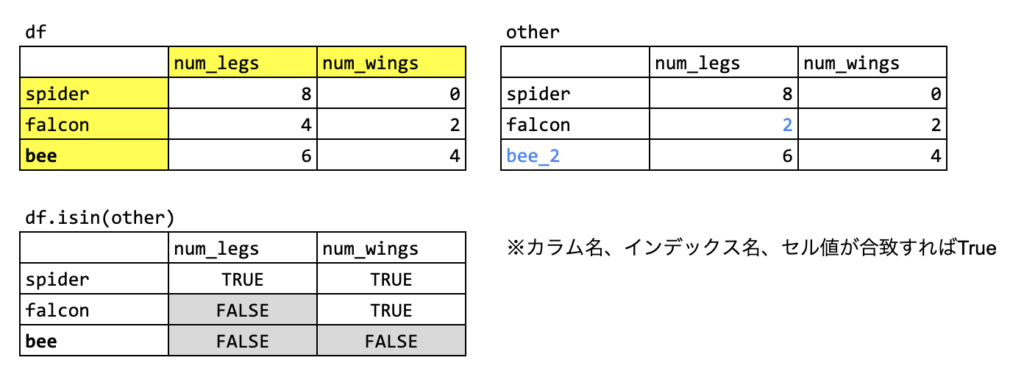
pd.all
- すべての要素がTrueであるかどうか(???) ← 全部TrueでなくてもTrueになるんだけど。
pd.all(0)、pd.all('index'):デフォルト値。行を減らし、行が「元の列ラベル」であるシリーズを返すpd.all(1)、pd.all('columns'):列を減らし、インデックスが「元のインデックス」であるシリーズを返す- isinと組み合わせて、index,columnsを使うとエラーになっ
df = pd.DataFrame({'col1': [True, True], 'col2': [True, False]})
df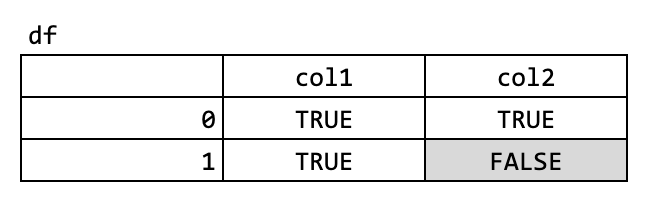
index方向に向かって(上から下向き)みた場合
- 以下、すべて同じ
df.all('index')df.all(0)df.all()
# df.all() のデフォルトは以下
df.all('index') # df.all(0)
# >> col1 True
# >> col2 False
# >> dtype: boolcolumns方向に向かって(左から右向き)と同じ
df.all('columns')df.all(1)
df.all('columns') # df.all(1)
# >> 0 True
# >> 1 False
# >> dtype: boolto_dict()
