目次
pd.crosstab(df[‘-‘],df[‘-‘],)
- カテゴリデータ(カテゴリカルデータ、質的データ)のカテゴリごとのサンプル数(出現回数・頻度)の算出などが可能。
- カテゴリごとの平均値などを算出したい場合は
pandas.pivot_table()を使う。 - 第1引数:index(行)になる
- 第2引数:columns(列)になる
pd.crosstab(df['Sex'], df['Pclass'])
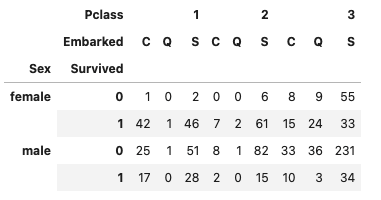
# 引数はリストでもよい。この場合マルチインデックスになる
pd.crosstab(
[df['Sex'], df['Survived']],
[df['Pclass'], df['Embarked']]
)
引数 margins、margins_name
- margins=True カテゴリの小計、全体の総計
- margins_name=’名前’
# 引数 margins=Trueとすると、各カテゴリの小計、全体の総計がでる
pd.crosstab(
[df['Sex'], df['Survived']],
[df['Pclass'], df['Embarked']],
margins=True
)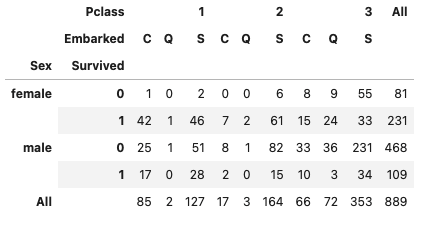
# 引数 margins=Trueのラベル名を変更する
pd.crosstab(
[df['Sex'], df['Survived']],
[df['Pclass'], df['Embarked']],
margins=True, margins_name='総計'
)