目次
『データサイエンス100本ノック構造化データ加工編ガイドブック』より
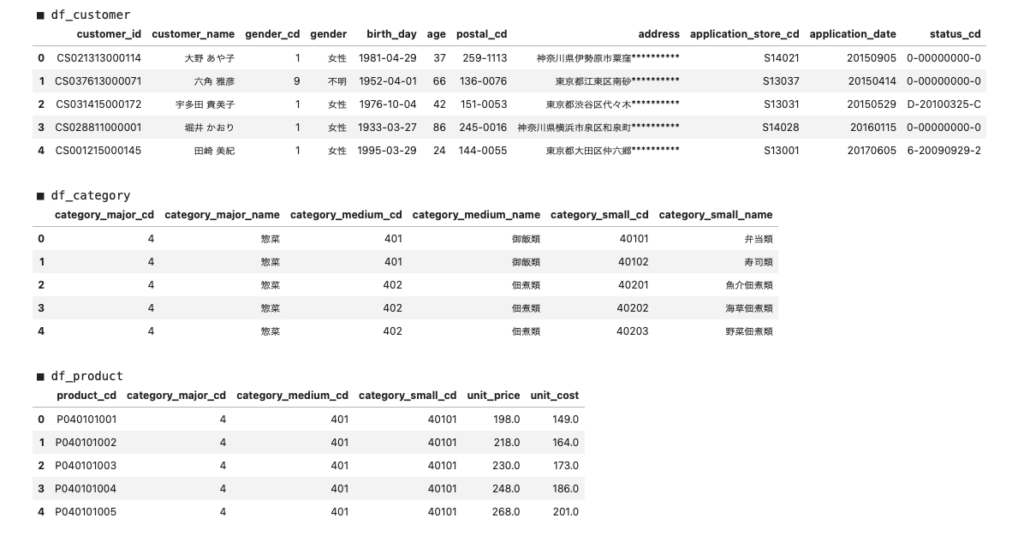
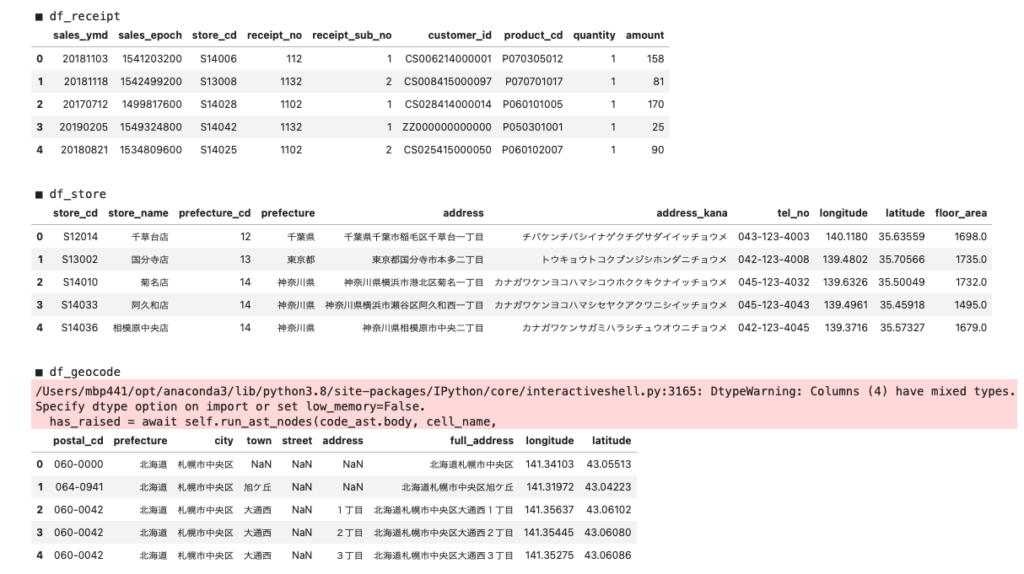
1.ローデータ
- 急ぎ使いたい場合は、1と3を使えばよい
import numpy as np
import pandas as pd
import pathlib
import re
url_customer = "https://miwadaice.info/sample_data/100knocks_csv/customer.csv"
url_category = "https://miwadaice.info/sample_data/100knocks_csv/category.csv"
url_product = "https://miwadaice.info/sample_data/100knocks_csv/product.csv"
url_receipt = "https://miwadaice.info/sample_data/100knocks_csv/receipt.csv"
url_store = "https://miwadaice.info/sample_data/100knocks_csv/store.csv"
url_geocode = "https://miwadaice.info/sample_data/100knocks_csv/geocode.csv"2.型変換なしver
# 型変換なしバージョン
df_customer = pd.read_csv(url_customer)
df_category = pd.read_csv(url_category)
df_product = pd.read_csv(url_product)
df_receipt = pd.read_csv(url_receipt)
df_store = pd.read_csv(url_store)
df_geocode = pd.read_csv(url_geocode)3.型変換ありver
- dtype の辞書をつくりたいときは
- {k: “” for k in df.columns.tolist()} で箱をつくっておくと楽
# 型指定ありバージョン
df_customer = pd.read_csv(url_customer,
dtype = {'customer_id': 'str',
'customer_name': 'str',
'gender_cd': 'str',
'gender': 'str',
# 'birth_day': '',
'age': np.int64,
'postal_cd': 'str',
'address': 'str',
'application_store_cd': 'str',
'application_date': 'str',
'status_cd': 'str'},
parse_dates=['birth_day']
)
df_customer['birth_day'] = df_customer['birth_day'].dt.date
df_category = pd.read_csv(url_category, dtype=str)
df_product = pd.read_csv(url_product,
dtype = {'product_cd': 'str',
'category_major_cd': 'str',
'category_medium_cd': 'str',
'category_small_cd': 'str',
'unit_price': np.float64,
'unit_cost': np.float64}
)
df_receipt = pd.read_csv(url_receipt,
dtype = {'sales_ymd': np.int64,
'sales_epoch': np.int64,
'store_cd': 'str',
'receipt_no': np.int64,
'receipt_sub_no': np.int64,
'customer_id': 'str',
'product_cd': 'str',
'quantity': np.int64,
'amount': np.int64}
)
df_store = pd.read_csv(url_store,
dtype = {'store_cd': 'str',
'store_name': 'str',
'prefecture_cd': 'str',
'prefecture': 'str',
'address': 'str',
'address_kana': 'str',
'tel_no': 'str',
'longitude': np.float64,
'latitude': np.float64,
'floor_area': np.float64,
}
)
df_geocode = pd.read_csv(url_geocode,
dtype = {'postal_cd': 'str',
'prefecture': 'str',
'city': 'str',
'town': 'str',
'street': 'str',
'address': 'str',
'full_address': 'str',
'longitude': np.float64,
'latitude': np.float64}
)import pandas as pd
import pathlib
import re
url_list = [url_customer, url_category, url_product, url_receipt, url_store, url_geocode]
# urlの末尾CSV名(拡張子除く)を取り出すregexパターン
p = re.compile(r"(\w*)(?:\.csv)$")
# サンプルデータを表示する
for url in url_list:
df = pd.read_csv(url)
csv_name = p.search(url).group(1)
print(f'\n■ df_{csv_name}')
display(df.head())