目次
pythonファイルで計測
- 例として、連続したn個の数値の合計を算出する関数test(n)の処理時間を計測する
timeit.timeit()関数に測定したいコードを文字列で渡す- すると、number回実行され、それにかかった時間が計測される
- numberのデフォルト値は100万。多すぎるため、変更すること
- 引数
globalに、global()を渡す。これがないと関数test(n)や変数nが認識されない - ↑結構、面倒。。。だから、次のlambdaのほうが使いやすいかも
- 最後、実行回数で割って1回あたりの処理時間を出す
import timeit
def test(n):
return sum(range(n))
n = 10000
loop = 1000
# timeit.timeit()関数に測定したいコードを渡す
result = timeit.timeit('test(n)', globals=globals(), number=loop)
print(result / loop)timeit.timeit()にlambda式を使う
import timeit
data = list(range(1_000))
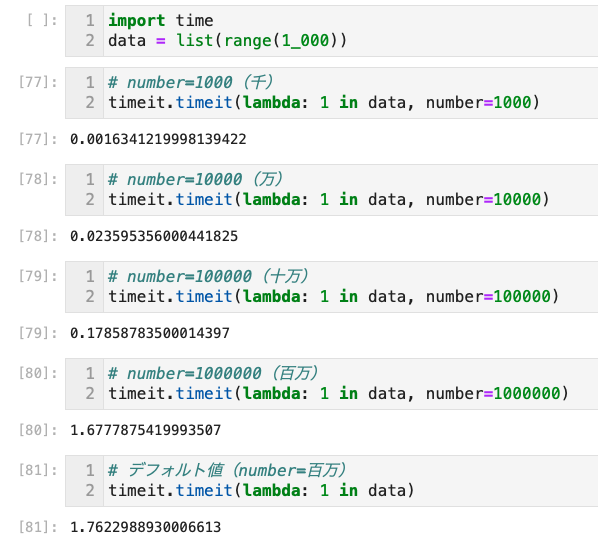
timeit.timeit(lambda: 1 in data, number=1000) # number=1〜1000ぐらいで様子見- 指定するコードは文字列でなく、呼び出し可能なオブジェクトでもよい
- よって、引数なしのlambda式で指定するとよい
- この場合、引数
globalsは指定しなくても良い - number(回数)はデフォルト百万、つまり計測結果も百万回実行した合計の計測時間になるため、本来、1回の実行時間を見たい場合はnumber(百万など)で割る必要がある
- また、number=1にすると小さすぎて分かりにくくなる
- 激重の処理時間計測にデフォルト値(百万回)を使うと、延々計測結果が表示されないので注意!
jupyterで計測する場合はコレ
- Jupyterでパフォーマンスを計測するならマジックコマンド「%%timeit」を使う
- その場合、importも不要
- わかりづらいが、2つの引数が使える(繰り返し数、ループ数)
%%timeit # 本来は適切な精度で計測するためにはデフォルトで使ったほうがよいであろう
function()
%%timeit -n 1 -r 1 # とにかく計測値をすぐにみたいとき
function()デフォルト値
- 繰り返し数:7
- ループ数:1000000
- よって、関数によっては計測するのに時間がかかる….

ループ数(n)を変える
- デフォルト100万だから、少なくしたいとき(すぐに目安時間をみたいときなど)
%%timeit -n 回数

繰り返し数(r)を変える
- デフォルト数は7、これを変えたいとき
%%timeit -r 回数(以下の例ではループ数も変えている)

- くりかえして、その実行時間を割って集計するからか。。。
timeの方がわかりやすい?
import time
start = time.time()
func()
end = time.time()
print(end - start)