
目次
重複行をすべて確認したい場合
- duplicatedはデフォルトでは、最初の値「以外」を重複(True)として扱う
- 重複した行をすべてを表示させたい場合は、keep=False(カンマ不要)をセットする
- sort_valueでソートした方が一覧で区別しやすい
# 以下は同じ結果
df[df['列A'].duplicated(keep=False)].sort_values('列A')
df[df.duplicated(subset=['列A'], keep=False).sort_values('列A')
# subset=['列A',列B',....]で複数列の組み合わせにおける重複の確認が可能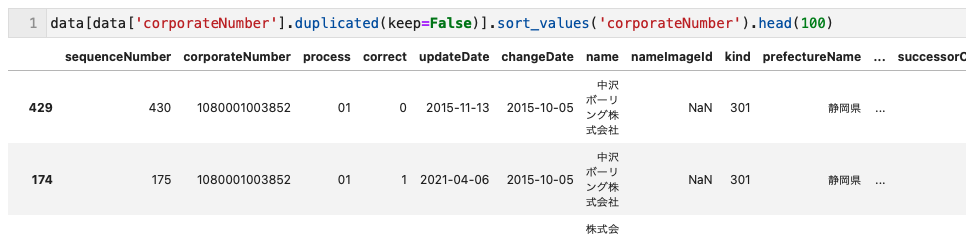
重複行を確認する、削除する
keep=first(デフォルト)
- duplicated :最初の値「以外」を、重複(True)とみなして表示する
- ~duplicated:重複でないものを残す(↓と同意)
- drop_duplicates:最初の値(first)をkeepし、他を削除する
keep=last
- duplicated :最後の値「以外」を、重複(True)とみなして表示する
- ~duplicated:重複でないものを残す(↓と同意)
- drop_duplicates:最後の値(last)をkeepし、他を削除する
keep=False
- duplicated :重複した行をすべて表示する
- ~duplicated:重複でないものを残す(↓と同意)
- drop_duplicates:重複した行をすべて削除する
df[
df[df['列A'].duplicated(keep=False)]
# 以下2つは同意
df[~df.duplicated()]
df.drop_duplicates()