目次
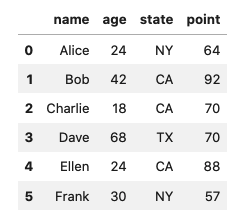
query
主な条件抽出の記法
- 上:Booleanインデックス法(Boolean選択法)
- 下:クエリー
df[df['age'] < 25]
df.query('age < 25')df[~(df['age'] < 25)]
df.query('not age < 25')df[(df['age'] >=24) & (df['age'] < 50)]
df.query('24 <= age < 50')df[df['age'] < (df['point'] / 3)]
df.query('age < point / 3')df[df['state'] == 'CA']
df.query('state == "CA"')df.query('state == ["NY", "TX"]')
df[df['state'].isin(['NY', 'TX'])]
df[(df['state'] == 'NY') | (df['state'] == 'TX')] #← NY or TXを含む
df.query(‘CH == “基地局” & 電力エリア == “中国電力”‘)df.query('name.str.endswith("e")', engine='python')
df.query('name.str.contains("li")', engine='python')df.query('name.str.match(".*i.*e")', engine='python')
# 文字列以外の型(数値)は1度str化して、そのstrから検索する
df.query('age.astype("str").str.endswidth("8"), engine='python')欠損値NaNがある場合の注意点
- NoneやNanがある列に対して文字列メソッドを適用して条件とするとエラーになるため、na=Falseとすると欠損値の行は抽出されない(Booleanインデックス法)
- queryでは以下はできないらしい
df[df['name'].str.endswith('e', na=False)]
# NaNをBooleanのFalseに変更できる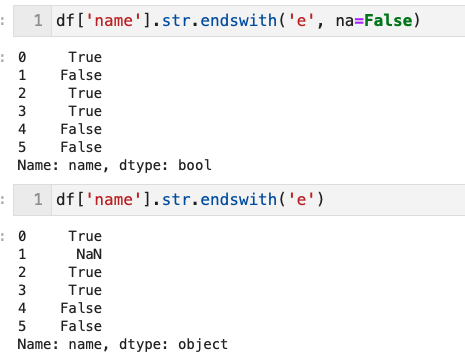
index列に対する条件
- index列(行名)に対する条件はindxで指定可能
df.query('index % 2 == 0')
# この場合、0行を含む偶数行が表示される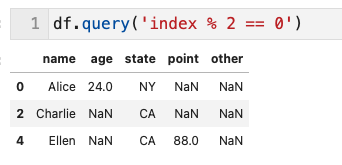
変数を使う
- query()メソッドの条件文字列で変数を使用するには変数の前に@をつける
- cf. queryメソッドは列名に「.」やスペースが入ると機能しない
val = 80
df.query('point > @val')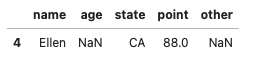
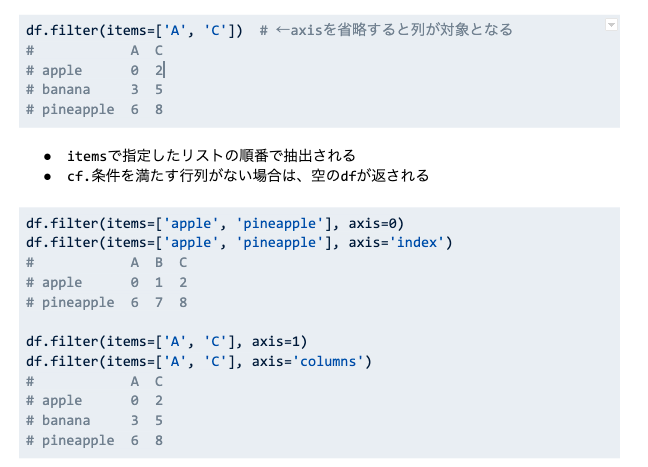
filter
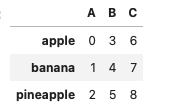
# サンプルDF
df = pd.DataFrame(
{'A': [0,1,2],
'B':[3,4,5],
'C':[6,7,8]},
index=['apple','banana','pineapple']
)