・2つのDataFrameの連結において ・merge()とjoin()なら、汎用的なmerge()を使ったほうが良い ・merge()は、pd.merge()のほうが使いやすそう(df.merge()より) ・キーに列を指定して連結するなら、merge()を使う ・インデックスで連結するなら、join()を使う(ただしmerge()でも可能)
目次
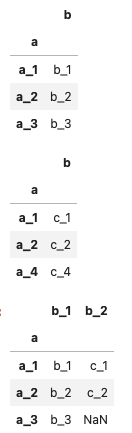
<merge>
キー(カラム・一列)
- pd.merge()とdf.merge()の二種類がある
- どちらを使っても結果は同じ
基本
- デフォルトでは、共通する列名の列でアライメント
- 例だと「列a」が共通した列になる。「on=’a’」が省略されている。明示した方がわかりやすい
- how=’inner’がデフォルト
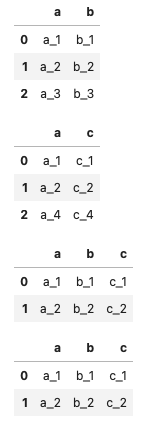
display(
df_ab,
df_ac,
pd.merge(df_ab, df_ac),
df_ab.merge(df_ac)
)
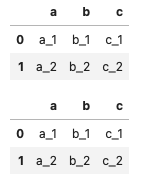
display(
pd.merge (df_ab, df_ac, on='a', how='inner'),
df_ab.merge(df_ac, on='a', how='inner'),
)
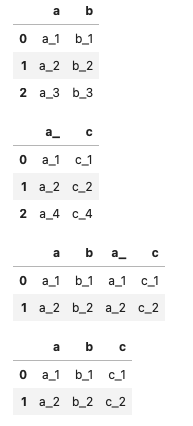
キーとなる列を指定
- デフォルトでは、共通する列名の列でアライメントされるが
- left_on、right_onで「異なる列(名)」でアライメントすることもできる
- 指定した列はそのまま残るため、省略しても問題がない場合はdrop()で削除する
df_ac_ = df_ac.rename(columns={'a':'a_'})
display(
df_ab,
df_ac_,
pd.merge(df_ab, df_ac_, left_on='a', right_on='a_'),
pd.merge(df_ab, df_ac_, left_on='a', right_on='a_').drop(columns='a_')
)
結合方法を指定
display(
pd.merge(df_ab, df_ac, on='a', how='inner', indicator=True), # indicator=Trueでマージしたデータの情報がわかる
pd.merge(df_ab, df_ac, on='a', how='left', indicator=True),
pd.merge(df_ab, df_ac, on='a', how='right', indicator=True),
pd.merge(df_ab, df_ac, on='a', how='outer', indicator=True),
)
列名が重複している場合
- 列名が重複している場合は、自動でsuffix(接尾語)が付与される
- そのsuffixを指定することも可能
df_ac_b = df_ac.rename(columns={'c': 'b'})
display(
df_ab,
df_ac_b,
pd.merge(df_ab, df_ac_b, on='a'),
pd.merge(df_ab, df_ac_b, on='a', suffixes=['_left', '_right']))
キー(カラム・複数列)
基本
- これまではキーとする列が1列だったが、複数の列をキーとしたい場合
- デフォルトでは、2つのDFの列a、xで共通する値だけが抽出される
df_abx = df_ab.assign(x=['x_2', 'x_2', 'x_3'])
df_acx = df_ac.assign(x=['x_1', 'x_2', 'x_2'])
display(
pd.merge(df_abx, df_acx),
pd.merge(df_abx, df_acx, on=['a', 'x'], how='inner'),
pd.merge(df_abx, df_acx, on=['a', 'x'], how='inner', indicator=True),
pd.merge(df_abx, df_acx, on='a')
)キーとなる列を指定
- 列「a」、列「x & x_」で共通する値だけが抽出される
- 指定した列はそのまま残るため、省略しても問題がない場合はdrop()で削除する
df_acx_ = df_acx.rename(columns={'x': 'x_'})
display(
df_abx,
df_acx_,
pd.merge(df_abx,df_acx_, left_on=['a', 'x'], right_on=['a', 'x_']),
pd.merge(df_abx,df_acx_, left_on=['a', 'x'], right_on=['a', 'x_']).drop(columns='x_')
)
結合方法を指定
display(df_abx, df_acx)
display(
df_abx,
df_acx,
pd.merge(df_abx, df_acx, on=['a', 'x'], how='inner', indicator=True), # <--defalut
pd.merge(df_abx, df_acx, on=['a', 'x'], how='left', indicator=True),
pd.merge(df_abx, df_acx, on=['a', 'x'], how='right', indicator=True),
pd.merge(df_abx, df_acx, on=['a', 'x'], how='outer', indicator=True)
)

キー列でソート
pd.merge(df_abx, df_acx, on=['a', 'x'], how='outer', sort=True)
キー(インデックス)
- キーにインデックス(行)を指定するやり方
- right_index , left_index=True で、rightまたはleft のインデックスがキーに指定できる
- 2つのDFにおいて、片方または両方でキーにインデックスを利用したい場合
df_ac_i = df_ac.set_index('a')
display(df_ab, df_ac_i)
pd.merge(df_ab, df_ac_i, left_on='a', right_index=True)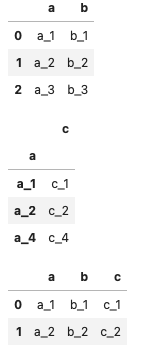
df_ab_i = df_ab.set_index('a')
display(df_ab_i, df_ac_i)
pd.merge(df_ab_i, df_ac_i, left_index=True, right_index=True)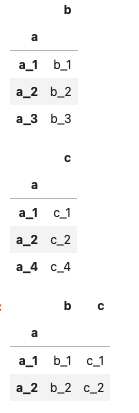
<join>
キー(インデックス)
インデックスで連結するならjoinがよい
- join() には merge()のように pd.join() はない
- how=’left’ がデフォルト( mergeは inner がデフォルト)
- 常に「インデックス」同士をキーとする
- join() の引数 on は2つのDFに対する指定なのでややこしい
- インデックスをキーとしない場合は merge() を使ったほうがわかりやすい
display(df_ab_i, df_ac_i)
print("-"*30)
display(
df_ab_i.join(df_ac_i),
df_ab_i.join(df_ac_i, on='a', how='left'), # デフォルト
df_ab_i.join(df_ac_i, on='a', how='inner'),
# 以下は使わない
df_ab_i.join(df_ac_i, on='a', how='right'),
df_ab_i.join(df_ac_i, on='a', how='outer'),
)- カラム名が同名なら、lsuffix or rsuffix で区別する
display(df_ab_1, df_ab_2)
df_ab_1.join(df_ab_2, on='a', lsuffix='_1', rsuffix='_2')