- sample
- https://miwadaice.info/wp-content/uploads/2022/06/unique_sample.csv
目次
Series.unique()
- 特定列のおけるユニーク要素を返す
- 戻り値:ndarray型(リストではない)
- デフォルトでNaNも含まれる

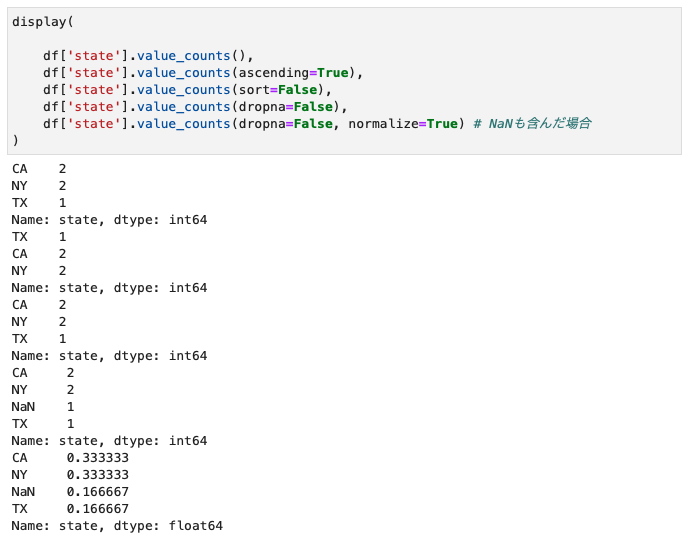
Series.value_counts()
- 特定列において、ユニークな要素の出現回数を出す
- 戻り値:Series
- デフォルト:降順ソート(多→少)、NaNは対象外
- ascending=True(昇順)
- sort=False(ソートされない)
- dropna=False(NaNをカウントする)
- normalize=True(標準化、合計が1)
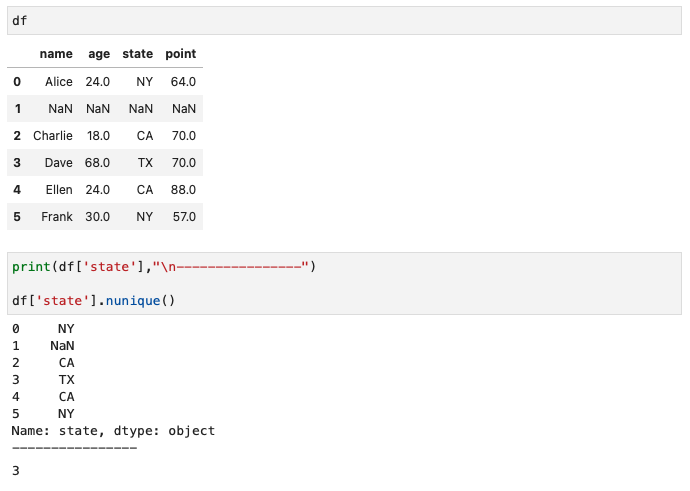
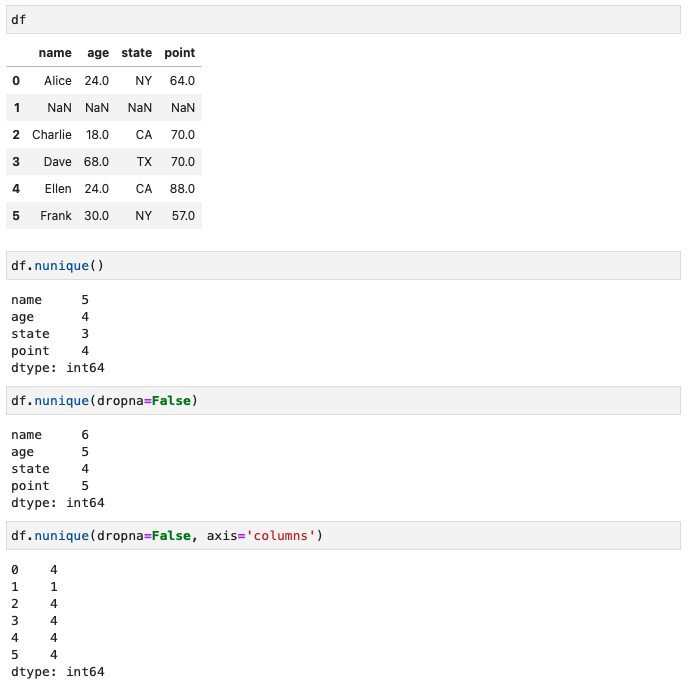
pandas.Series.nunique()
- 特定列におけるユニークな要素の個数を出す
- 戻り値:int型
- デフォルト:NaNは除外(dropna=Falseを指定すれば含んだ結果が表示される)
- uniqueがn個ある、の「n」unique
- ユニークな要素の個数を「列ごと」に表示する
- デフォルト:NaNは除外(dropna=Falseを指定すれば含んだ結果が表示される)
- デフォルト:列ごとの値(axis=’columns’を指定すれば行ごとの値を返す)
ユニークな要素の値のリスト
- dfにおけるユニーク要素でNaNを含ませないやり方(下から2段目は間違っている)
- df[‘state’].value_counts().index.values.tolist()

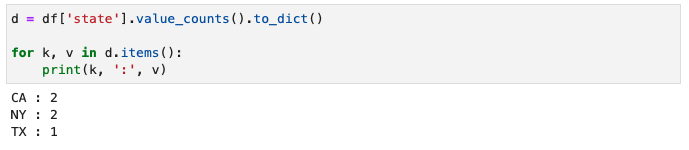
ユニークな要素の頻度(出現回数)
- ユニークな要素それぞれの出現回数を得るには、value_counts()で取得したSeriesの値にアクセスすればよい

ユニークな要素とその出現回数をループで辞書へ格納