目次
2つのDFを比較するには「この」の方法がベスト
- ただし、2つのDFの列名はあわせておく必要あり
- 比較する列を切り出しておくとよい
- 理由:他列に余計なNaNや文字列が含まれていると比較できないため
- あくまで比較したい列だけを抜き出して実施する
compareを使う
- 注)
compareは列名と行数が同じでないとエラーになるはず。
参考URL:https://ryamashina.com/itml/20210427/
テストデータ作成
import pandas as pd
df1 = pd.DataFrame(
dict(
a=[2, 4, 6],
b=[1, 2, 3],
c=[3, 6, 9],
))
df2 = pd.DataFrame(
dict(
a=[20, 4, 6],
b=[1, 2, 3],
c=[3, 6, 90],
))
# copyは()が必要
df1_copy = df1.copy()
display(df1,df2)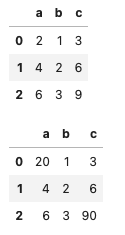
2つのデータフレームが合致しているか?(True/False)
df1.equals(df2)
# >>> False
df1.equals(df1_copy)
# >>> True値の違うindexとcolumnを特定する(compare)
df1.compare(df2)の場合、df1:self(比較元), df2:other(比較先) になる- 結果、「差異がある行数と列」および「その値」が確認できる
- 重要:カラムが一致していないとエラーになる
df_comp = df1.compare(df2)
df_comp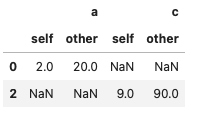
# 見やすくする
df_comp.fillna('-')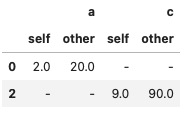
compareの結果から差異のある列を特定する
diff_col = df_comp.columns.droplevel(1).unique()
diff_col
# >>> Index(['a', 'c'], dtype='object')compareの結果から列を指定して違いのある行を特定する
df_comp['a'].dropna(how='all') # defalutでは'any'なので隣がNanだと行自体が消えるため、allにする
df_comp['c'].dropna(how='all')